 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Image Context Extraction with Graph Neural Networks and Sentence Embeddings on the DOM tree
Aug 26, 2021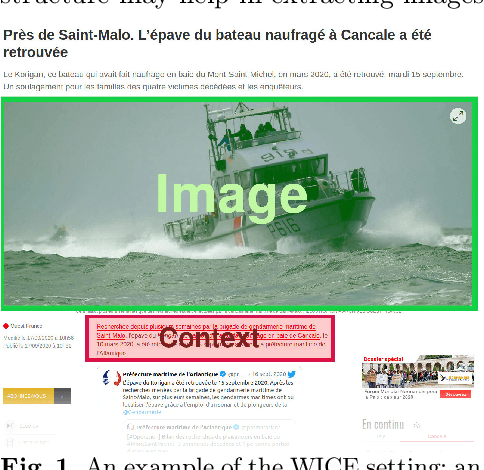
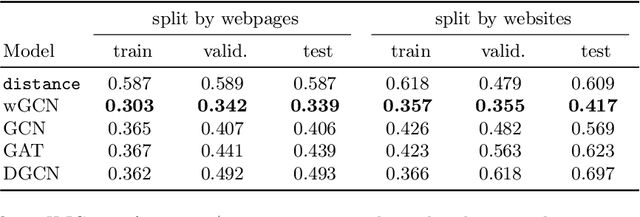
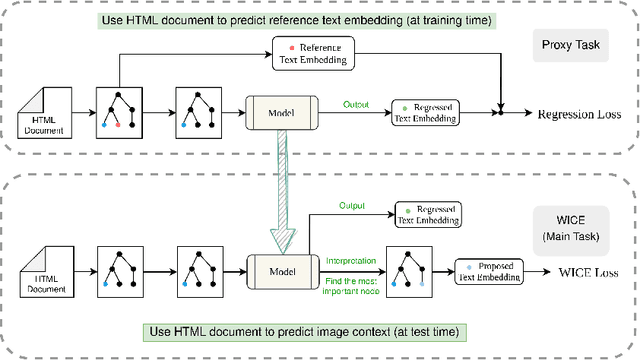
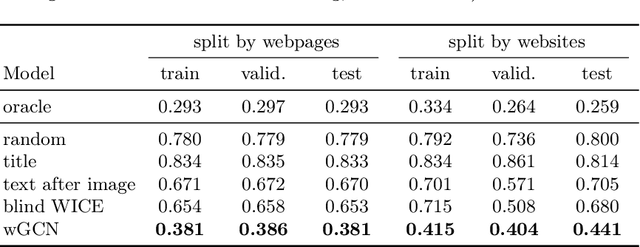
Web Image Context Extraction (WICE) consists in obtaining the textual information describing an image using the content of the surrounding webpage. A common preprocessing step before performing WICE is to render the content of the webpage. When done at a large scale (e.g., for search engine indexation), it may become very computationally costly (up to several seconds per page). To avoid this cost, we introduce a novel WICE approach that combines Graph Neural Networks (GNNs) and Natural Language Processing models. Our method relies on a graph model containing both node types and text as features. The model is fed through several blocks of GNNs to extract the textual context. Since no labeled WICE dataset with ground truth exists, we train and evaluate the GNNs on a proxy task that consists in finding the semantically closest text to the image caption. We then interpret importance weights to find the most relevant text nodes and define them as the image context. Thanks to GNNs, our model is able to encode both structural and semantic information from the webpage. We show that our approach gives promising results to help address the large-scale WICE problem using only HTML data.
PKSpell: Data-Driven Pitch Spelling and Key Signature Estimation
Jul 27, 2021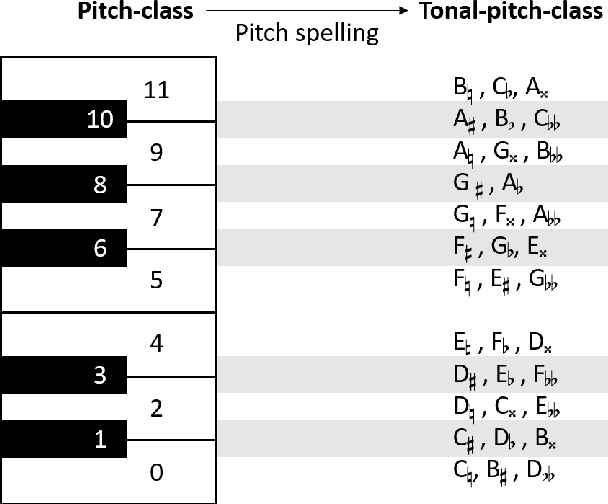
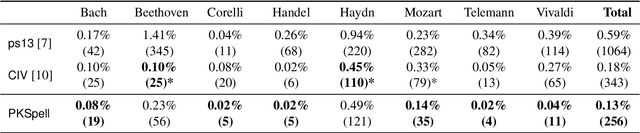

We present PKSpell: a data-driven approach for the joint estimation of pitch spelling and key signatures from MIDI files. Both elements are fundamental for the production of a full-fledged musical score and facilitate many MIR tasks such as harmonic analysis, section identification, melodic similarity, and search in a digital music library. We design a deep recurrent neural network model that only requires information readily available in all kinds of MIDI files, including performances, or other symbolic encodings. We release a model trained on the ASAP dataset. Our system can be used with these pre-trained parameters and is easy to integrate into a MIR pipeline. We also propose a data augmentation procedure that helps retraining on small datasets. PKSpell achieves strong key signature estimation performance on a challenging dataset. Most importantly, this model establishes a new state-of-the-art performance on the MuseData pitch spelling dataset without retraining.