 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWYSIWYE: An Algebra for Expressing Spatial and Textual Rules for Visual Information Extraction
Sep 27, 2016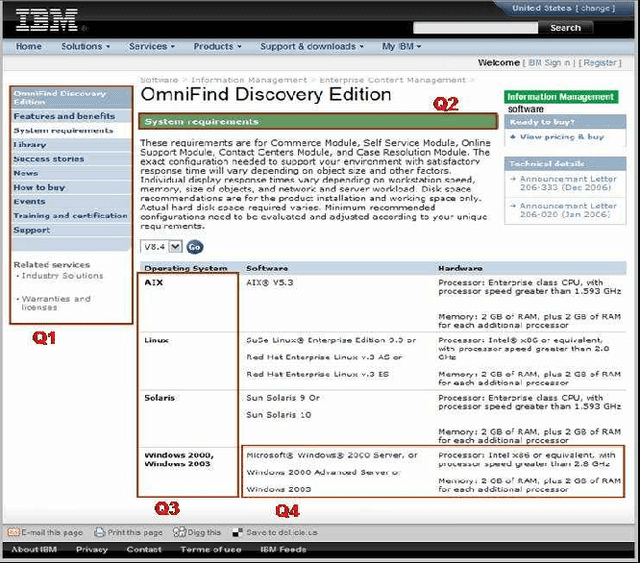
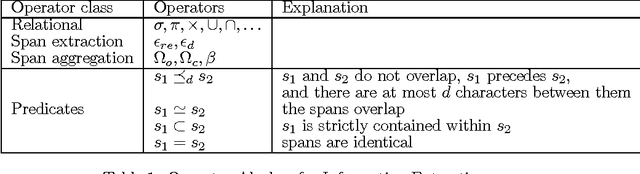

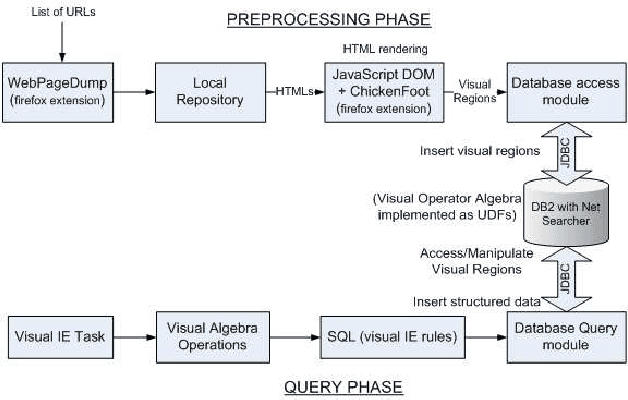
The visual layout of a webpage can provide valuable clues for certain types of Information Extraction (IE) tasks. In traditional rule based IE frameworks, these layout cues are mapped to rules that operate on the HTML source of the webpages. In contrast, we have developed a framework in which the rules can be specified directly at the layout level. This has many advantages, since the higher level of abstraction leads to simpler extraction rules that are largely independent of the source code of the page, and, therefore, more robust. It can also enable specification of new types of rules that are not otherwise possible. To the best of our knowledge, there is no general framework that allows declarative specification of information extraction rules based on spatial layout. Our framework is complementary to traditional text based rules framework and allows a seamless combination of spatial layout based rules with traditional text based rules. We describe the algebra that enables such a system and its efficient implementation using standard relational and text indexing features of a relational database. We demonstrate the simplicity and efficiency of this system for a task involving the extraction of software system requirements from software product pages.