 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Story of QoS Prediction in Vehicular Communication: From Radio Environment Statistics to Network-Access Throughput Prediction
Feb 23, 2023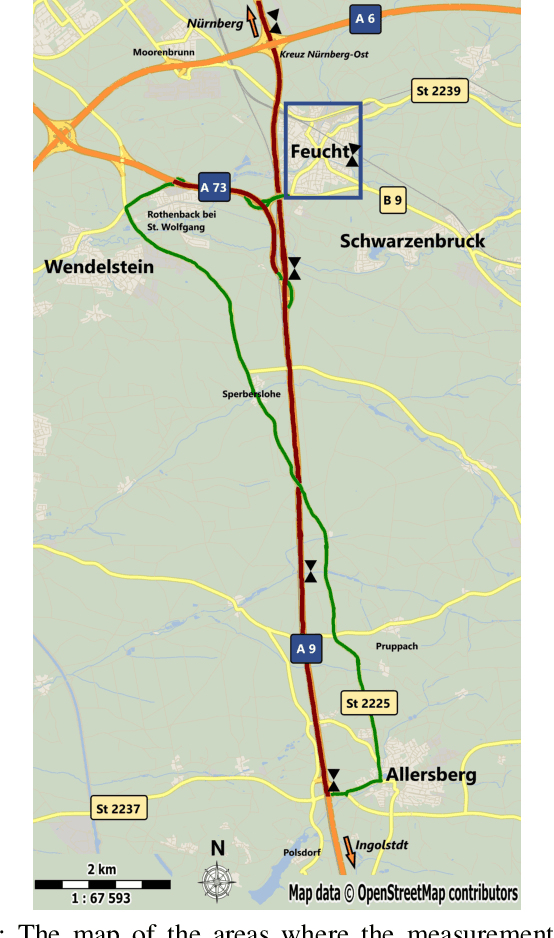
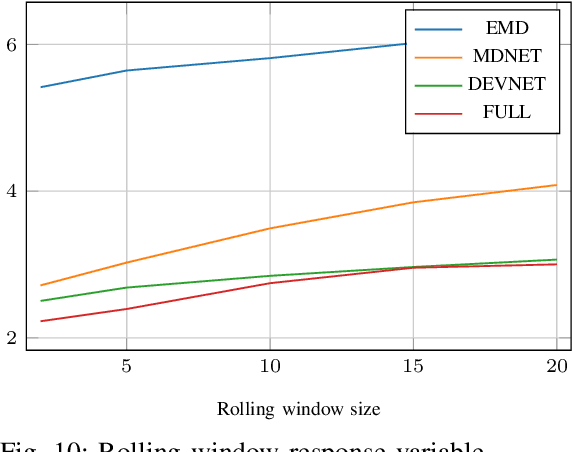
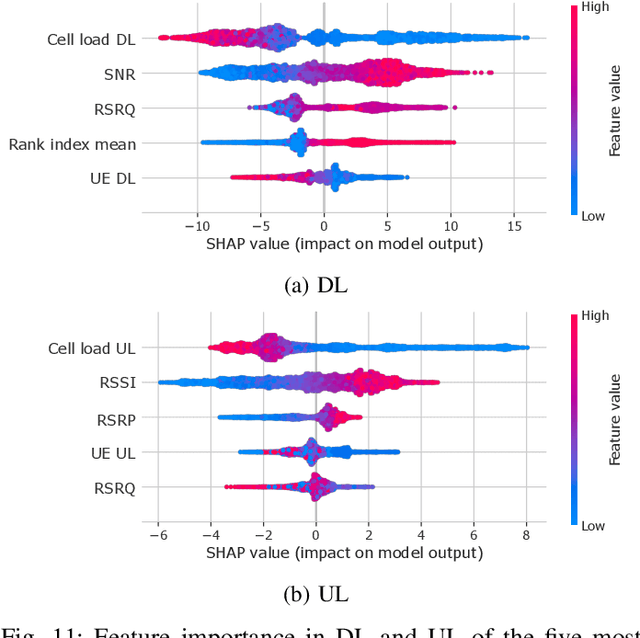
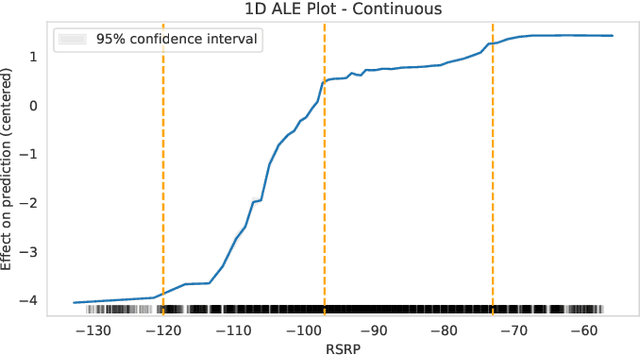
As cellular networks evolve towards the 6th Generation (6G), Machine Learning (ML) is seen as a key enabling technology to improve the capabilities of the network. ML provides a methodology for predictive systems, which, in turn, can make networks become proactive. This proactive behavior of the network can be leveraged to sustain, for example, a specific Quality of Service (QoS) requirement. With predictive Quality of Service (pQoS), a wide variety of new use cases, both safety- and entertainment-related, are emerging, especially in the automotive sector. Therefore, in this work, we consider maximum throughput prediction enhancing, for example, streaming or HD mapping applications. We discuss the entire ML workflow highlighting less regarded aspects such as the detailed sampling procedures, the in-depth analysis of the dataset characteristics, the effects of splits in the provided results, and the data availability. Reliable ML models need to face a lot of challenges during their lifecycle. We highlight how confidence can be built on ML technologies by better understanding the underlying characteristics of the collected data. We discuss feature engineering and the effects of different splits for the training processes, showcasing that random splits might overestimate performance by more than twofold. Moreover, we investigate diverse sets of input features, where network information proved to be most effective, cutting the error by half. Part of our contribution is the validation of multiple ML models within diverse scenarios. We also use Explainable AI (XAI) to show that ML can learn underlying principles of wireless networks without being explicitly programmed. Our data is collected from a deployed network that was under full control of the measurement team and covered different vehicular scenarios and radio environments.
Supervised Learning for Physical Layer based Message Authentication in URLLC scenarios
Sep 13, 2019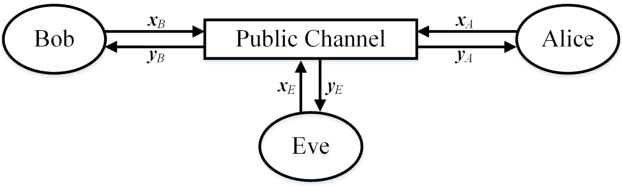
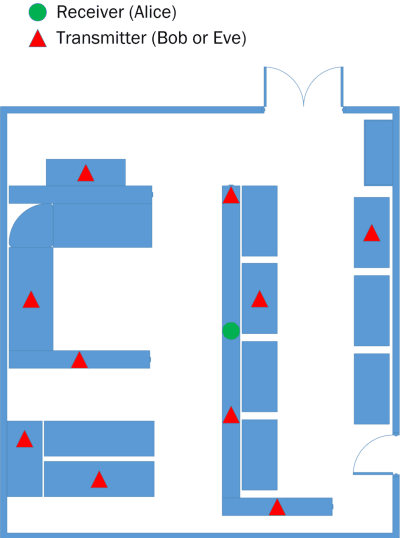
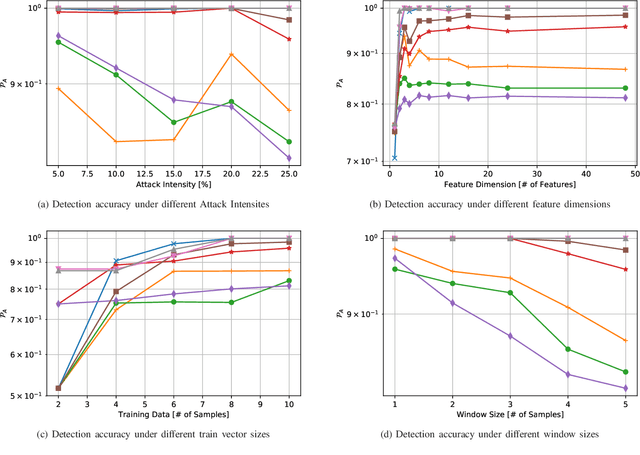
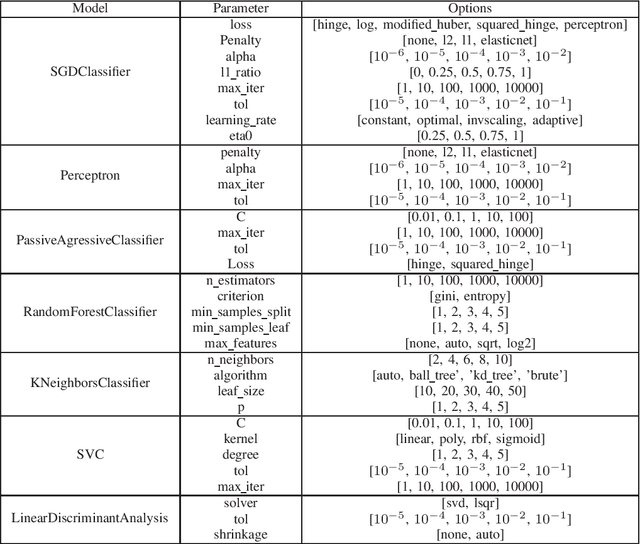
PHYSEC based message authentication can, as an alternative to conventional security schemes, be applied within \gls{urllc} scenarios in order to meet the requirement of secure user data transmissions in the sense of authenticity and integrity. In this work, we investigate the performance of supervised learning classifiers for discriminating legitimate transmitters from illegimate ones in such scenarios. We further present our methodology of data collection using \gls{sdr} platforms and the data processing pipeline including e.g. necessary preprocessing steps. Finally, the performance of the considered supervised learning schemes under different side conditions is presented.