 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Your Model: Iterative Label Improvement and Robust Training by Confidence Based Filtering and Dataset Partitioning
Feb 19, 2020

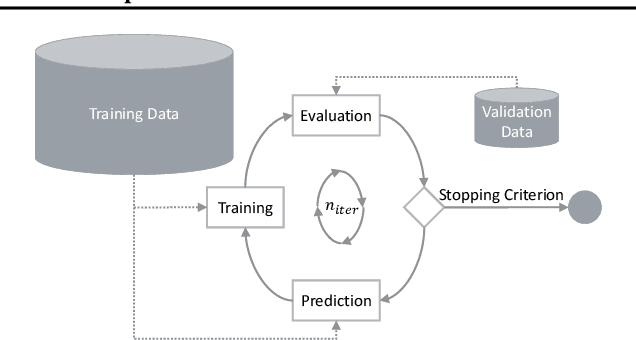

State-of-the-art, high capacity deep neural networks not only require large amounts of labelled training data, they are also highly susceptible to label errors in this data, typically resulting in large efforts and costs and therefore limiting the applicability of deep learning. To alleviate this issue, we propose a novel meta training and labelling scheme that is able to use inexpensive unlabelled data by taking advantage of the generalization power of deep neural networks. We show experimentally that by solely relying on one network architecture and our proposed scheme of iterative training and prediction steps, both label quality and resulting model accuracy can be improved significantly. Our method achieves state-of-the-art results, while being architecture agnostic and therefore broadly applicable. Compared to other methods dealing with erroneous labels, our approach does neither require another network to be trained, nor does it necessarily need an additional, highly accurate reference label set. Instead of removing samples from a labelled set, our technique uses additional sensor data without the need for manual labelling.