 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVid-Net: Enhanced Semantic Segmentation of UAV Aerial Videos by Embedding Temporal Information
Nov 29, 2020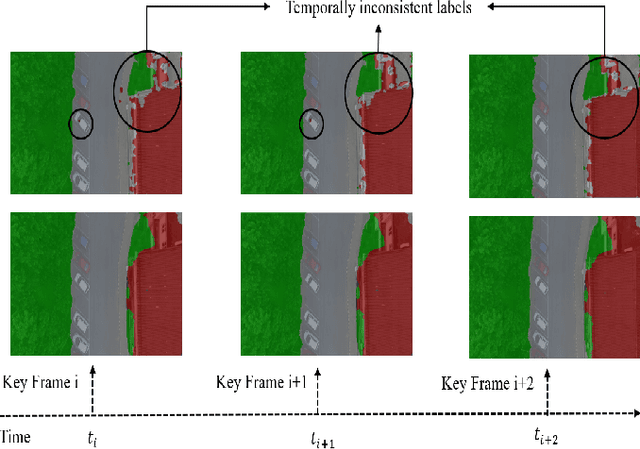
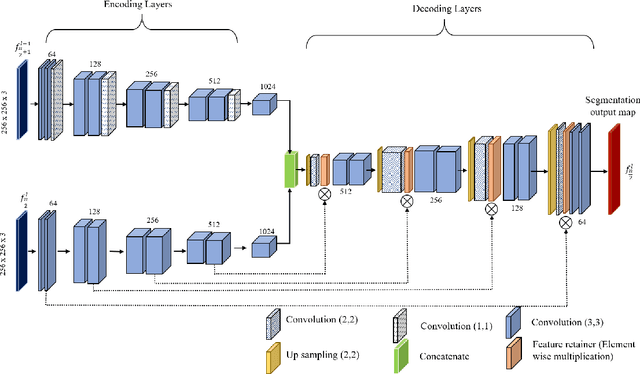
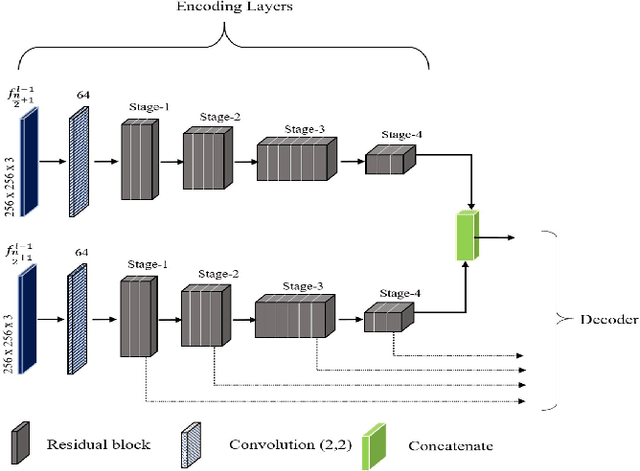

Semantic segmentation of aerial videos has been extensively used for decision making in monitoring environmental changes, urban planning, and disaster management. The reliability of these decision support systems is dependent on the accuracy of the video semantic segmentation algorithms. The existing CNN based video semantic segmentation methods have enhanced the image semantic segmentation methods by incorporating an additional module such as LSTM or optical flow for computing temporal dynamics of the video which is a computational overhead. The proposed research work modifies the CNN architecture by incorporating temporal information to improve the efficiency of video semantic segmentation. In this work, an enhanced encoder-decoder based CNN architecture (UVid-Net) is proposed for UAV video semantic segmentation. The encoder of the proposed architecture embeds temporal information for temporally consistent labelling. The decoder is enhanced by introducing the feature retainer module, which aids in the accurate localization of the class labels. The proposed UVid-Net architecture for UAV video semantic segmentation is quantitatively evaluated on an extended ManipalUAVid dataset. The performance metric mIoU of 0.79 has been observed which is significantly greater than the other state-of-the-art algorithms. Further, the proposed work produced promising results even for the pre-trained model of UVid-Net on the urban street scene with fine-tuning the final layer on UAV aerial videos.