 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Extraction of Uyghur Medicine Knowledge with Edge Computing
Jan 13, 2024Medical knowledge extraction methods based on edge computing deploy deep learning models on edge devices to achieve localized entity and relation extraction. This approach avoids transferring substantial sensitive data to cloud data centers, effectively safeguarding the privacy of healthcare services. However, existing relation extraction methods mainly employ a sequential pipeline approach, which classifies relations between determined entities after entity recognition. This mode faces challenges such as error propagation between tasks, insufficient consideration of dependencies between the two subtasks, and the neglect of interrelations between different relations within a sentence. To address these challenges, a joint extraction model with parameter sharing in edge computing is proposed, named CoEx-Bert. This model leverages shared parameterization between two models to jointly extract entities and relations. Specifically, CoEx-Bert employs two models, each separately sharing hidden layer parameters, and combines these two loss functions for joint backpropagation to optimize the model parameters. Additionally, it effectively resolves the issue of entity overlapping when extracting knowledge from unstructured Uyghur medical texts by considering contextual relations. Finally, this model is deployed on edge devices for real-time extraction and inference of Uyghur medical knowledge. Experimental results demonstrate that CoEx-Bert outperforms existing state-of-the-art methods, achieving accuracy, recall, and F1 scores of 90.65\%, 92.45\%, and 91.54\%, respectively, in the Uyghur traditional medical literature dataset. These improvements represent a 6.45\% increase in accuracy, a 9.45\% increase in recall, and a 7.95\% increase in F1 score compared to the baseline.
Edge-Enabled Anomaly Detection and Information Completion for Social Network Knowledge Graphs
Jan 13, 2024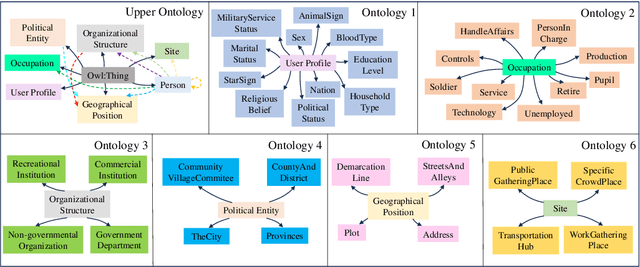

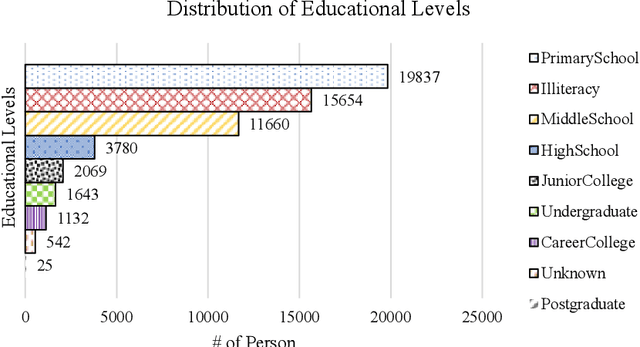

In the rapidly advancing information era, various human behaviors are being precisely recorded in the form of data, including identity information, criminal records, and communication data. Law enforcement agencies can effectively maintain social security and precisely combat criminal activities by analyzing the aforementioned data. In comparison to traditional data analysis methods, deep learning models, relying on the robust computational power in cloud centers, exhibit higher accuracy in extracting data features and inferring data. However, within the architecture of cloud centers, the transmission of data from end devices introduces significant latency, hindering real-time inference of data. Furthermore, low-latency edge computing architectures face limitations in direct deployment due to relatively weak computing and storage capacities of nodes. To address these challenges, a lightweight distributed knowledge graph completion architecture is proposed. Firstly, we introduce a lightweight distributed knowledge graph completion architecture that utilizes knowledge graph embedding for data analysis. Subsequently, to filter out substandard data, a personnel data quality assessment method named PDQA is proposed. Lastly, we present a model pruning algorithm that significantly reduces the model size while maximizing performance, enabling lightweight deployment. In experiments, we compare the effects of 11 advanced models on completing the knowledge graph of public security personnel information. The results indicate that the RotatE model outperforms other models significantly in knowledge graph completion, with the pruned model size reduced by 70\%, and hits@10 reaching 86.97\%.}