 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration-Free Induced Magnetic Field Indoor and Outdoor Positioning via Data-Driven Modeling
Jan 31, 2026Induced magnetic field (IMF)-based localization offers a robust alternative to wave-based positioning technologies due to its resilience to non-line-of-sight conditions, environmental dynamics, and wireless interference. However, existing magnetic localization systems typically rely on analytical field inversion, manual calibration, or environment-specific fingerprinting, limiting their scalability and transferability. This paper presents a data-driven IMF localization framework that directly maps induced magnetic field measurements to spatial coordinates using supervised learning, eliminating explicit environment-specific calibration. By replacing explicit field modeling with learning-based inference, the proposed approach captures nonlinear field interactions and environmental effects. An orientation-invariant feature representation enables rotation-independent deployment. The system is evaluated across multiple indoor environments and an outdoor deployment. Benchmarking against classical and deep learning baselines shows that a Random Forest regressor achieves sub-20 cm accuracy in 2D and sub-30 cm in 3D localization. Cross-environment validation demonstrates that models trained indoors generalize to outdoor environments without retraining. We further analyze scalability by varying transmitter spacing, showing that coverage and accuracy can be balanced through deployment density. Overall, this work demonstrates that data-driven IMF localization is a scalable and transferable solution for real-world positioning.
Depth-Copy-Paste: Multimodal and Depth-Aware Compositing for Robust Face Detection
Dec 12, 2025Data augmentation is crucial for improving the robustness of face detection systems, especially under challenging conditions such as occlusion, illumination variation, and complex environments. Traditional copy paste augmentation often produces unrealistic composites due to inaccurate foreground extraction, inconsistent scene geometry, and mismatched background semantics. To address these limitations, we propose Depth Copy Paste, a multimodal and depth aware augmentation framework that generates diverse and physically consistent face detection training samples by copying full body person instances and pasting them into semantically compatible scenes. Our approach first employs BLIP and CLIP to jointly assess semantic and visual coherence, enabling automatic retrieval of the most suitable background images for the given foreground person. To ensure high quality foreground masks that preserve facial details, we integrate SAM3 for precise segmentation and Depth-Anything to extract only the non occluded visible person regions, preventing corrupted facial textures from being used in augmentation. For geometric realism, we introduce a depth guided sliding window placement mechanism that searches over the background depth map to identify paste locations with optimal depth continuity and scale alignment. The resulting composites exhibit natural depth relationships and improved visual plausibility. Extensive experiments show that Depth Copy Paste provides more diverse and realistic training data, leading to significant performance improvements in downstream face detection tasks compared with traditional copy paste and depth free augmentation methods.
SynRailObs: A Synthetic Dataset for Obstacle Detection in Railway Scenarios
May 16, 2025Detecting potential obstacles in railway environments is critical for preventing serious accidents. Identifying a broad range of obstacle categories under complex conditions requires large-scale datasets with precisely annotated, high-quality images. However, existing publicly available datasets fail to meet these requirements, thereby hindering progress in railway safety research. To address this gap, we introduce SynRailObs, a high-fidelity synthetic dataset designed to represent a diverse range of weather conditions and geographical features. Furthermore, diffusion models are employed to generate rare and difficult-to-capture obstacles that are typically challenging to obtain in real-world scenarios. To evaluate the effectiveness of SynRailObs, we perform experiments in real-world railway environments, testing on both ballasted and ballastless tracks across various weather conditions. The results demonstrate that SynRailObs holds substantial potential for advancing obstacle detection in railway safety applications. Models trained on this dataset show consistent performance across different distances and environmental conditions. Moreover, the model trained on SynRailObs exhibits zero-shot capabilities, which are essential for applications in security-sensitive domains. The data is available in https://www.kaggle.com/datasets/qiushi910/synrailobs.
Enrich the content of the image Using Context-Aware Copy Paste
Jul 11, 2024Data augmentation remains a widely utilized technique in deep learning, particularly in tasks such as image classification, semantic segmentation, and object detection. Among them, Copy-Paste is a simple yet effective method and gain great attention recently. However, existing Copy-Paste often overlook contextual relevance between source and target images, resulting in inconsistencies in generated outputs. To address this challenge, we propose a context-aware approach that integrates Bidirectional Latent Information Propagation (BLIP) for content extraction from source images. By matching extracted content information with category information, our method ensures cohesive integration of target objects using Segment Anything Model (SAM) and You Only Look Once (YOLO). This approach eliminates the need for manual annotation, offering an automated and user-friendly solution. Experimental evaluations across diverse datasets demonstrate the effectiveness of our method in enhancing data diversity and generating high-quality pseudo-images across various computer vision tasks.
A Universal Railway Obstacle Detection System based on Semi-supervised Segmentation And Optical Flow
Jun 27, 2024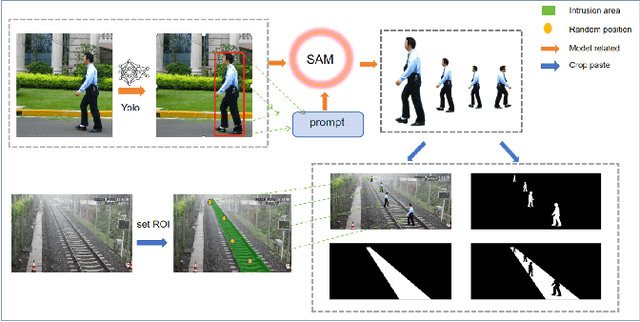
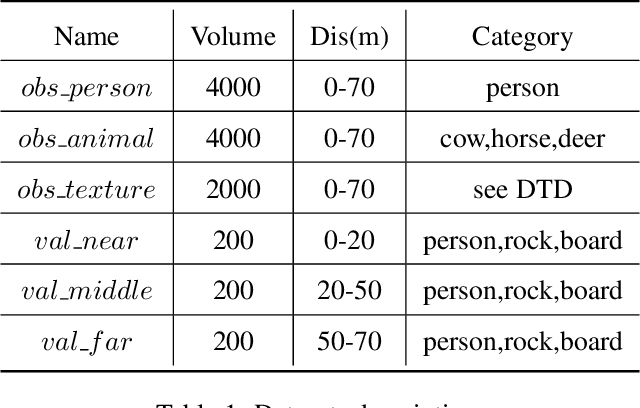
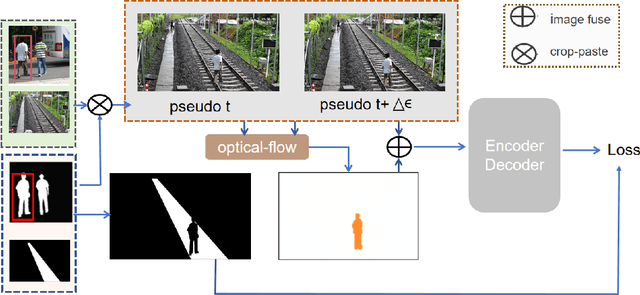
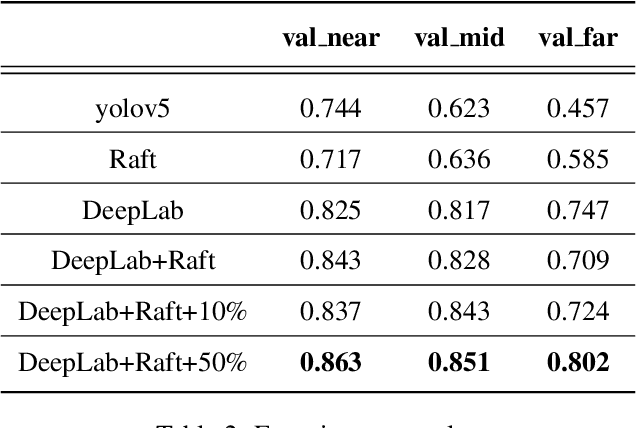
Detecting obstacles in railway scenarios is both crucial and challenging due to the wide range of obstacle categories and varying ambient conditions such as weather and light. Given the impossibility of encompassing all obstacle categories during the training stage, we address this out-of-distribution (OOD) issue with a semi-supervised segmentation approach guided by optical flow clues. We reformulate the task as a binary segmentation problem instead of the traditional object detection approach. To mitigate data shortages, we generate highly realistic synthetic images using Segment Anything (SAM) and YOLO, eliminating the need for manual annotation to produce abundant pixel-level annotations. Additionally, we leverage optical flow as prior knowledge to train the model effectively. Several experiments are conducted, demonstrating the feasibility and effectiveness of our approach.
FaceSkin: A Privacy Preserving Facial skin patch Dataset for multi Attributes classification
Aug 09, 2023



Human facial skin images contain abundant textural information that can serve as valuable features for attribute classification, such as age, race, and gender. Additionally, facial skin images offer the advantages of easy collection and minimal privacy concerns. However, the availability of well-labeled human skin datasets with a sufficient number of images is limited. To address this issue, we introduce a dataset called FaceSkin, which encompasses a diverse range of ages and races. Furthermore, to broaden the application scenarios, we incorporate synthetic skin-patches obtained from 2D and 3D attack images, including printed paper, replays, and 3D masks. We evaluate the FaceSkin dataset across distinct categories and present experimental results demonstrating its effectiveness in attribute classification, as well as its potential for various downstream tasks, such as Face anti-spoofing and Age estimation.
Enhancing Mobile Privacy and Security: A Face Skin Patch-Based Anti-Spoofing Approach
Aug 09, 2023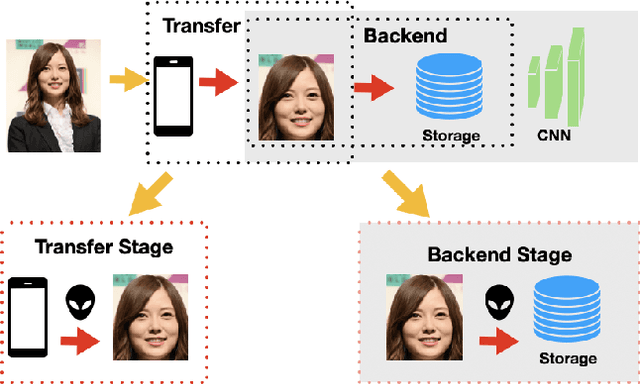
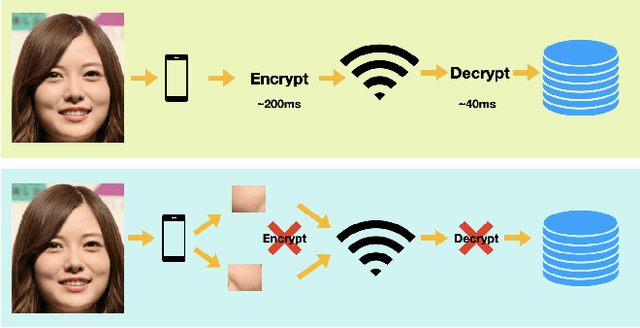
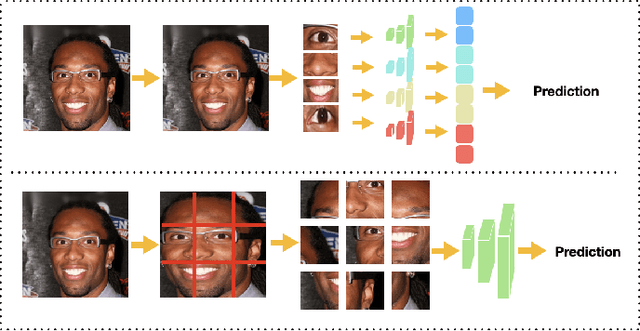
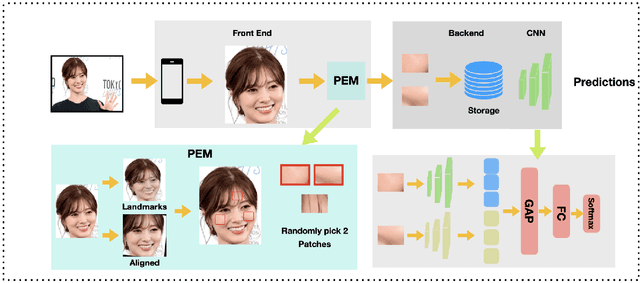
As Facial Recognition System(FRS) is widely applied in areas such as access control and mobile payments due to its convenience and high accuracy. The security of facial recognition is also highly regarded. The Face anti-spoofing system(FAS) for face recognition is an important component used to enhance the security of face recognition systems. Traditional FAS used images containing identity information to detect spoofing traces, however there is a risk of privacy leakage during the transmission and storage of these images. Besides, the encryption and decryption of these privacy-sensitive data takes too long compared to inference time by FAS model. To address the above issues, we propose a face anti-spoofing algorithm based on facial skin patches leveraging pure facial skin patch images as input, which contain no privacy information, no encryption or decryption is needed for these images. We conduct experiments on several public datasets, the results prove that our algorithm has demonstrated superiority in both accuracy and speed.