 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Driven EEG Channel Selection for Brain-Assisted Speech Enhancement
Nov 23, 2023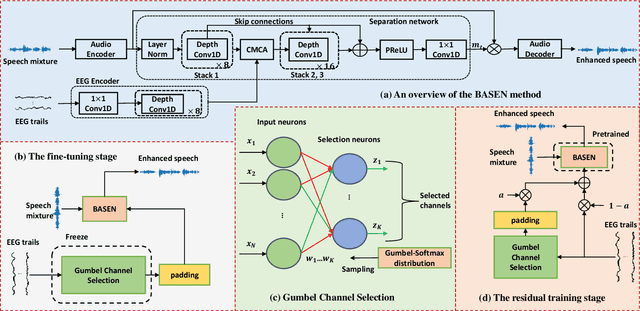

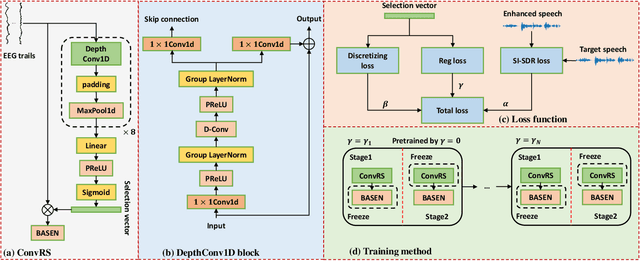
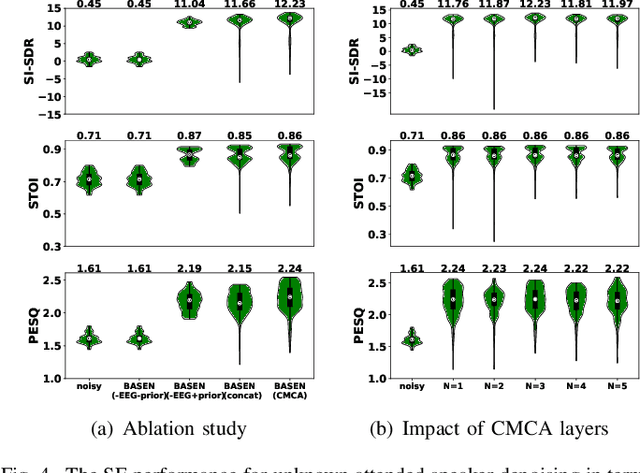
Speech enhancement is widely used as a front-end to improve the speech quality in many audio systems, while it is still hard to extract the target speech in multi-talker conditions without prior information on the speaker identity. It was shown by auditory attention decoding that the attended speaker can be revealed by the electroencephalogram (EEG) of the listener implicitly. In this work, we therefore propose a novel end-to-end brain-assisted speech enhancement network (BASEN), which incorporates the listeners' EEG signals and adopts a temporal convolutional network together with a convolutional multi-layer cross attention module to fuse EEG-audio features. Considering that an EEG cap with sparse channels exhibits multiple benefits and in practice many electrodes might contribute marginally, we further propose two channel selection methods, called residual Gumbel selection and convolutional regularization selection. They are dedicated to tackling the issues of training instability and duplicated channel selections, respectively. Experimental results on a public dataset show the superiority of the proposed baseline BASEN over existing approaches. The proposed channel selection methods can significantly reduce the amount of informative EEG channels with a negligible impact on the performance.
BASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
May 17, 2023


Time-domain single-channel speech enhancement (SE) still remains challenging to extract the target speaker without any prior information on multi-talker conditions. It has been shown via auditory attention decoding that the brain activity of the listener contains the auditory information of the attended speaker. In this paper, we thus propose a novel time-domain brain-assisted SE network (BASEN) incorporating electroencephalography (EEG) signals recorded from the listener for extracting the target speaker from monaural speech mixtures. The proposed BASEN is based on the fully-convolutional time-domain audio separation network. In order to fully leverage the complementary information contained in the EEG signals, we further propose a convolutional multi-layer cross attention module to fuse the dual-branch features. Experimental results on a public dataset show that the proposed model outperforms the state-of-the-art method in several evaluation metrics. The reproducible code is available at https://github.com/jzhangU/Basen.git.