 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Benchmark Towards Multi-Modal Face Anti-Spoofing Under Surveillance Scenarios
Mar 29, 2021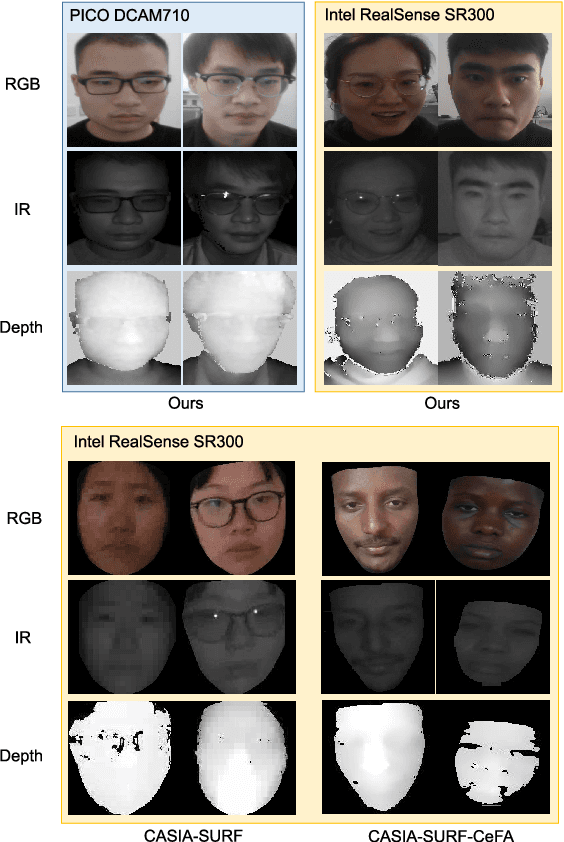
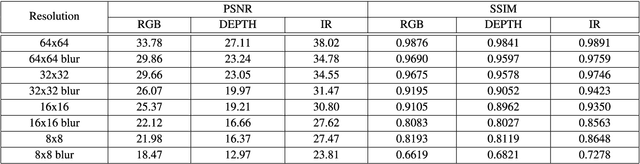

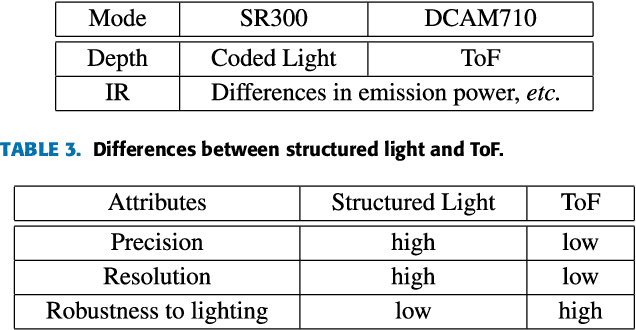
Face Anti-spoofing (FAS) is a challenging problem due to complex serving scenarios and diverse face presentation attack patterns. Especially when captured images are low-resolution, blurry, and coming from different domains, the performance of FAS will degrade significantly. The existing multi-modal FAS datasets rarely pay attention to the cross-domain problems under deployment scenarios, which is not conducive to the study of model performance. To solve these problems, we explore the fine-grained differences between multi-modal cameras and construct a cross-domain multi-modal FAS dataset under surveillance scenarios called GREAT-FASD-S. Besides, we propose an Attention based Face Anti-spoofing network with Feature Augment (AFA) to solve the FAS towards low-quality face images. It consists of the depthwise separable attention module (DAM) and the multi-modal based feature augment module (MFAM). Our model can achieve state-of-the-art performance on the CASIA-SURF dataset and our proposed GREAT-FASD-S dataset.
* Published in: IEEE Access