 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-Fly VLA Adaptation via Test-Time Reinforcement Learning
Jan 13, 2026Vision-Language-Action models have recently emerged as a powerful paradigm for general-purpose robot learning, enabling agents to map visual observations and natural-language instructions into executable robotic actions. Though popular, they are primarily trained via supervised fine-tuning or training-time reinforcement learning, requiring explicit fine-tuning phases, human interventions, or controlled data collection. Consequently, existing methods remain unsuitable for challenging simulated- or physical-world deployments, where robots must respond autonomously and flexibly to evolving environments. To address this limitation, we introduce a Test-Time Reinforcement Learning for VLAs (TT-VLA), a framework that enables on-the-fly policy adaptation during inference. TT-VLA formulates a dense reward mechanism that leverages step-by-step task-progress signals to refine action policies during test time while preserving the SFT/RL-trained priors, making it an effective supplement to current VLA models. Empirical results show that our approach enhances overall adaptability, stability, and task success in dynamic, previously unseen scenarios under simulated and real-world settings. We believe TT-VLA offers a principled step toward self-improving, deployment-ready VLAs.
Two-scale Neural Networks for Partial Differential Equations with Small Parameters
Feb 27, 2024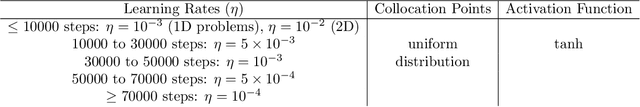
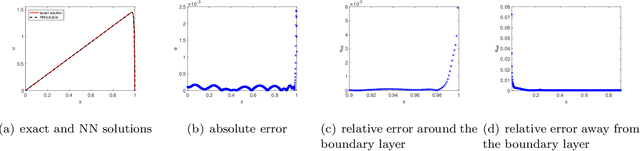

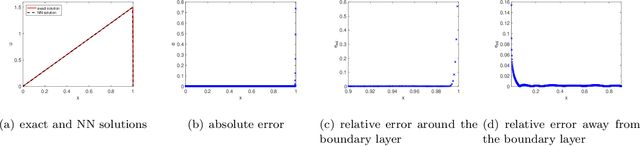
We propose a two-scale neural network method for solving partial differential equations (PDEs) with small parameters using physics-informed neural networks (PINNs). We directly incorporate the small parameters into the architecture of neural networks. The proposed method enables solving PDEs with small parameters in a simple fashion, without adding Fourier features or other computationally taxing searches of truncation parameters. Various numerical examples demonstrate reasonable accuracy in capturing features of large derivatives in the solutions caused by small parameters.