 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Robust Neural Machine Translation: A Transformer Case Study
Dec 31, 2020
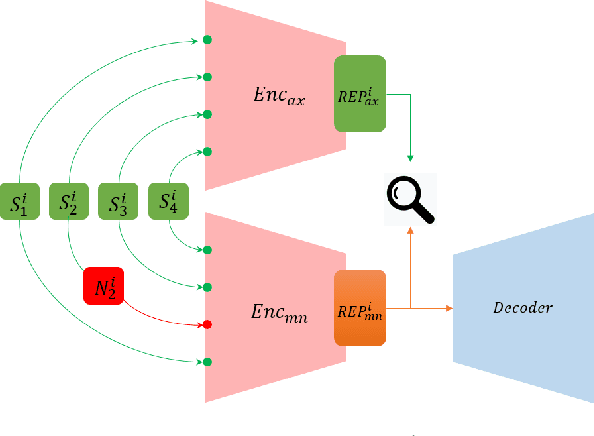

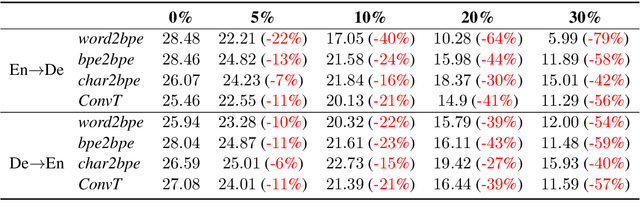
Transformers (Vaswani et al., 2017) have brought a remarkable improvement in the performance of neural machine translation (NMT) systems, but they could be surprisingly vulnerable to noise. Accordingly, we tried to investigate how noise breaks Transformers and if there exist solutions to deal with such issues. There is a large body of work in the NMT literature on analyzing the behaviour of conventional models for the problem of noise but it seems Transformers are understudied in this context. Therefore, we introduce a novel data-driven technique to incorporate noise during training. This idea is comparable to the well-known fine-tuning strategy. Moreover, we propose two new extensions to the original Transformer, that modify the neural architecture as well as the training process to handle noise. We evaluated our techniques to translate the English--German pair in both directions. Experimental results show that our models have a higher tolerance to noise. More specifically, they perform with no deterioration where up to 10% of entire test words are infected by noise.