 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Posteriors for Chi-squared Divergence based PAC-Bayesian Bounds and Comparison with KL-divergence based Optimal Posteriors and Cross-Validation Procedure
Aug 14, 2020



We investigate optimal posteriors for recently introduced \cite{begin2016pac} chi-squared divergence based PAC-Bayesian bounds in terms of nature of their distribution, scalability of computations, and test set performance. For a finite classifier set, we deduce bounds for three distance functions: KL-divergence, linear and squared distances. Optimal posterior weights are proportional to deviations of empirical risks, usually with subset support. For uniform prior, it is sufficient to search among posteriors on classifier subsets ordered by these risks. We show the bound minimization for linear distance as a convex program and obtain a closed-form expression for its optimal posterior. Whereas that for squared distance is a quasi-convex program under a specific condition, and the one for KL-divergence is non-convex optimization (a difference of convex functions). To compute such optimal posteriors, we derive fast converging fixed point (FP) equations. We apply these approaches to a finite set of SVM regularization parameter values to yield stochastic SVMs with tight bounds. We perform a comprehensive performance comparison between our optimal posteriors and known KL-divergence based posteriors on a variety of UCI datasets with varying ranges and variances in risk values, etc. Chi-squared divergence based posteriors have weaker bounds and worse test errors, hinting at an underlying regularization by KL-divergence based posteriors. Our study highlights the impact of divergence function on the performance of PAC-Bayesian classifiers. We compare our stochastic classifiers with cross-validation based deterministic classifier. The latter has better test errors, but ours is more sample robust, has quantifiable generalization guarantees, and is computationally much faster.
Optimal PAC-Bayesian Posteriors for Stochastic Classifiers and their use for Choice of SVM Regularization Parameter
Dec 14, 2019
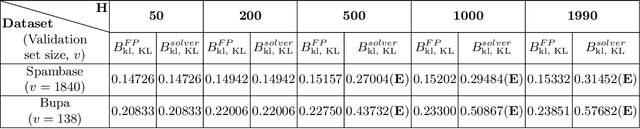
PAC-Bayesian set up involves a stochastic classifier characterized by a posterior distribution on a classifier set, offers a high probability bound on its averaged true risk and is robust to the training sample used. For a given posterior, this bound captures the trade off between averaged empirical risk and KL-divergence based model complexity term. Our goal is to identify an optimal posterior with the least PAC-Bayesian bound. We consider a finite classifier set and 5 distance functions: KL-divergence, its Pinsker's and a sixth degree polynomial approximations; linear and squared distances. Linear distance based model results in a convex optimization problem. We obtain closed form expression for its optimal posterior. For uniform prior, this posterior has full support with weights negative-exponentially proportional to number of misclassifications. Squared distance and Pinsker's approximation bounds are possibly quasi-convex and are observed to have single local minimum. We derive fixed point equations (FPEs) using partial KKT system with strict positivity constraints. This obviates the combinatorial search for subset support of the optimal posterior. For uniform prior, exponential search on a full-dimensional simplex can be limited to an ordered subset of classifiers with increasing empirical risk values. These FPEs converge rapidly to a stationary point, even for a large classifier set when a solver fails. We apply these approaches to SVMs generated using a finite set of SVM regularization parameter values on 9 UCI datasets. These posteriors yield stochastic SVM classifiers with tight bounds. KL-divergence based bound is the tightest, but is computationally expensive due to non-convexity and multiple calls to a root finding algorithm. Optimal posteriors for all 5 distance functions have lowest 10% test error values on most datasets, with linear distance being the easiest to obtain.
* 56 pages, 6 Figures, ACML 2019 conference paper with supplementary material