 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindi audio-video-Deepfake (HAV-DF): A Hindi language-based Audio-video Deepfake Dataset
Nov 23, 2024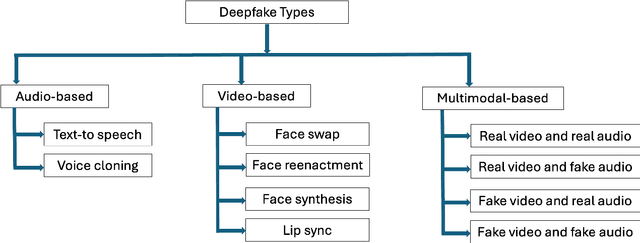



Deepfakes offer great potential for innovation and creativity, but they also pose significant risks to privacy, trust, and security. With a vast Hindi-speaking population, India is particularly vulnerable to deepfake-driven misinformation campaigns. Fake videos or speeches in Hindi can have an enormous impact on rural and semi-urban communities, where digital literacy tends to be lower and people are more inclined to trust video content. The development of effective frameworks and detection tools to combat deepfake misuse requires high-quality, diverse, and extensive datasets. The existing popular datasets like FF-DF (FaceForensics++), and DFDC (DeepFake Detection Challenge) are based on English language.. Hence, this paper aims to create a first novel Hindi deep fake dataset, named ``Hindi audio-video-Deepfake'' (HAV-DF). The dataset has been generated using the faceswap, lipsyn and voice cloning methods. This multi-step process allows us to create a rich, varied dataset that captures the nuances of Hindi speech and facial expressions, providing a robust foundation for training and evaluating deepfake detection models in a Hindi language context. It is unique of its kind as all of the previous datasets contain either deepfake videos or synthesized audio. This type of deepfake dataset can be used for training a detector for both deepfake video and audio datasets. Notably, the newly introduced HAV-DF dataset demonstrates lower detection accuracy's across existing detection methods like Headpose, Xception-c40, etc. Compared to other well-known datasets FF-DF, and DFDC. This trend suggests that the HAV-DF dataset presents deeper challenges to detect, possibly due to its focus on Hindi language content and diverse manipulation techniques. The HAV-DF dataset fills the gap in Hindi-specific deepfake datasets, aiding multilingual deepfake detection development.