 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Large Language Models for Automated Feedback Generation in Learning Programming Problem Solving
Mar 18, 2025Providing effective feedback is important for student learning in programming problem-solving. In this sense, Large Language Models (LLMs) have emerged as potential tools to automate feedback generation. However, their reliability and ability to identify reasoning errors in student code remain not well understood. This study evaluates the performance of four LLMs (GPT-4o, GPT-4o mini, GPT-4-Turbo, and Gemini-1.5-pro) on a benchmark dataset of 45 student solutions. We assessed the models' capacity to provide accurate and insightful feedback, particularly in identifying reasoning mistakes. Our analysis reveals that 63\% of feedback hints were accurate and complete, while 37\% contained mistakes, including incorrect line identification, flawed explanations, or hallucinated issues. These findings highlight the potential and limitations of LLMs in programming education and underscore the need for improvements to enhance reliability and minimize risks in educational applications.
Exploring the Relationship Between Feature Attribution Methods and Model Performance
May 22, 2024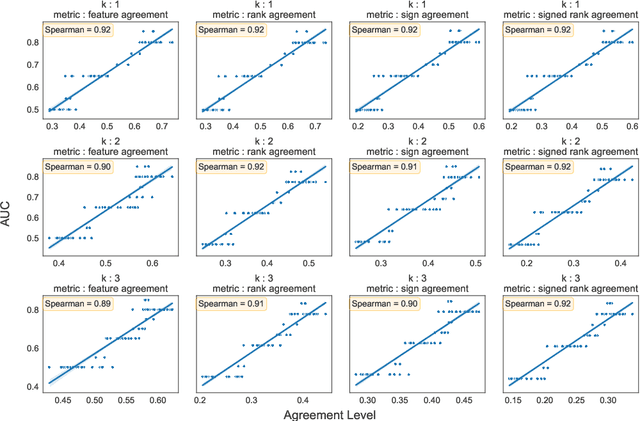

Machine learning and deep learning models are pivotal in educational contexts, particularly in predicting student success. Despite their widespread application, a significant gap persists in comprehending the factors influencing these models' predictions, especially in explainability within education. This work addresses this gap by employing nine distinct explanation methods and conducting a comprehensive analysis to explore the correlation between the agreement among these methods in generating explanations and the predictive model's performance. Applying Spearman's correlation, our findings reveal a very strong correlation between the model's performance and the agreement level observed among the explanation methods.