 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Asian Religions Have in Common? An Unsupervised Text Analytics Exploration
Dec 20, 2019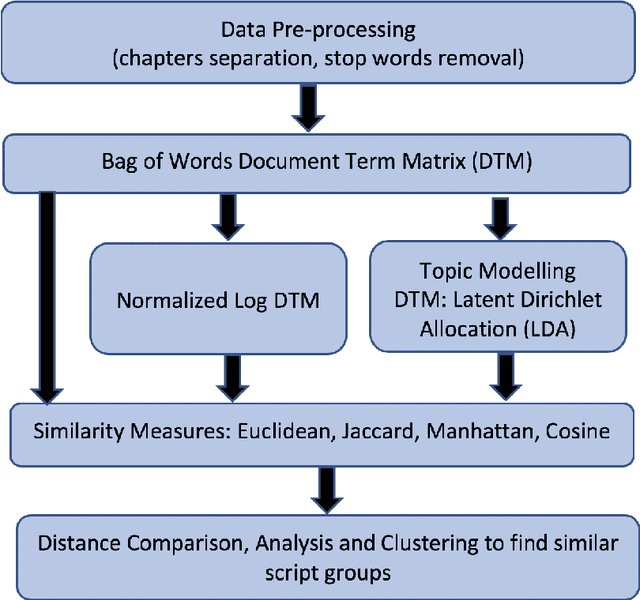



The main source of various religious teachings is their sacred texts which vary from religion to religion based on different factors like the geographical location or time of the birth of a particular religion. Despite these differences, there could be similarities between the sacred texts based on what lessons it teaches to its followers. This paper attempts to find the similarity using text mining techniques. The corpus consisting of Asian (Tao Te Ching, Buddhism, Yogasutra, Upanishad) and non-Asian (four Bible texts) is used to explore findings of similarity measures like Euclidean, Manhattan, Jaccard and Cosine on raw Document Term Frequency [DTM], normalized DTM which reveals similarity based on word usage. The performance of Supervised learning algorithms like K-Nearest Neighbor [KNN], Support Vector Machine [SVM] and Random Forest is measured based on its accuracy to predict correct scared text for any given chapter in the corpus. The K-means clustering visualizations on Euclidean distances of raw DTM reveals that there exists a pattern of similarity among these sacred texts with Upanishads and Tao Te Ching is the most similar text in the corpus.