 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile asymmetric multi-legged locomotion: contact planning via geometric mechanics and spin model duality
Feb 09, 2026Legged robot research is presently focused on bipedal or quadrupedal robots, despite capabilities to build robots with many more legs to potentially improve locomotion performance. This imbalance is not necessarily due to hardware limitations, but rather to the absence of principled control frameworks that explain when and how additional legs improve locomotion performance. In multi-legged systems, coordinating many simultaneous contacts introduces a severe curse of dimensionality that challenges existing modeling and control approaches. As an alternative, multi-legged robots are typically controlled using low-dimensional gaits originally developed for bipeds or quadrupeds. These strategies fail to exploit the new symmetries and control opportunities that emerge in higher-dimensional systems. In this work, we develop a principled framework for discovering new control structures in multi-legged locomotion. We use geometric mechanics to reduce contact-rich locomotion planning to a graph optimization problem, and propose a spin model duality framework from statistical mechanics to exploit symmetry breaking and guide optimal gait reorganization. Using this approach, we identify an asymmetric locomotion strategy for a hexapod robot that achieves a forward speed of 0.61 body lengths per cycle (a 50% improvement over conventional gaits). The resulting asymmetry appears at both the control and hardware levels. At the control level, the body orientation oscillates asymmetrically between fast clockwise and slow counterclockwise turning phases for forward locomotion. At the hardware level, two legs on the same side remain unactuated and can be replaced with rigid parts without degrading performance. Numerical simulations and robophysical experiments validate the framework and reveal novel locomotion behaviors that emerge from symmetry reforming in high-dimensional embodied systems.
Deep Convolutional Architectures for Extrapolative Forecast in Time-dependent Flow Problems
Sep 18, 2022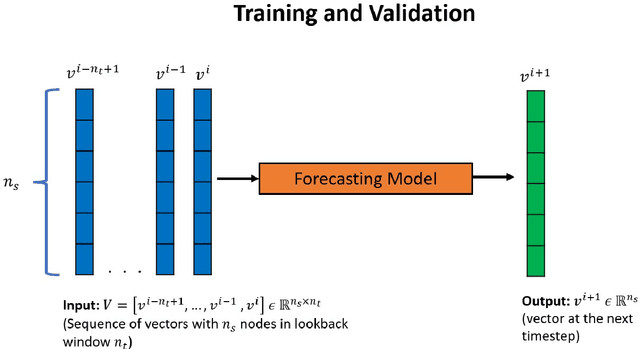

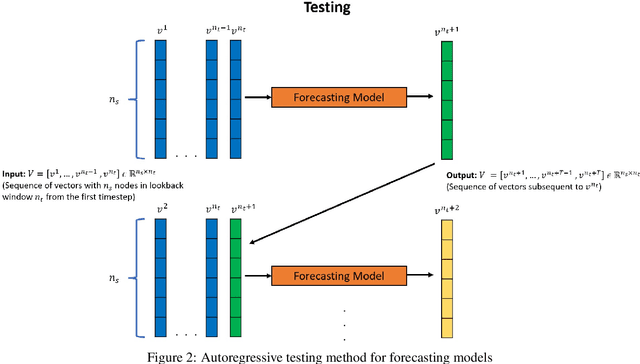

Physical systems whose dynamics are governed by partial differential equations (PDEs) find applications in numerous fields, from engineering design to weather forecasting. The process of obtaining the solution from such PDEs may be computationally expensive for large-scale and parameterized problems. In this work, deep learning techniques developed especially for time-series forecasts, such as LSTM and TCN, or for spatial-feature extraction such as CNN, are employed to model the system dynamics for advection dominated problems. These models take as input a sequence of high-fidelity vector solutions for consecutive time-steps obtained from the PDEs and forecast the solutions for the subsequent time-steps using auto-regression; thereby reducing the computation time and power needed to obtain such high-fidelity solutions. The models are tested on numerical benchmarks (1D Burgers' equation and Stoker's dam break problem) to assess the long-term prediction accuracy, even outside the training domain (extrapolation). Non-intrusive reduced-order modelling techniques such as deep auto-encoder networks are utilized to compress the high-fidelity snapshots before feeding them as input to the forecasting models in order to reduce the complexity and the required computations in the online and offline stages. Deep ensembles are employed to perform uncertainty quantification of the forecasting models, which provides information about the variance of the predictions as a result of the epistemic uncertainties.
A comparative study of various Deep Learning techniques for spatio-temporal Super-Resolution reconstruction of Forced Isotropic Turbulent flows
Jul 07, 2021


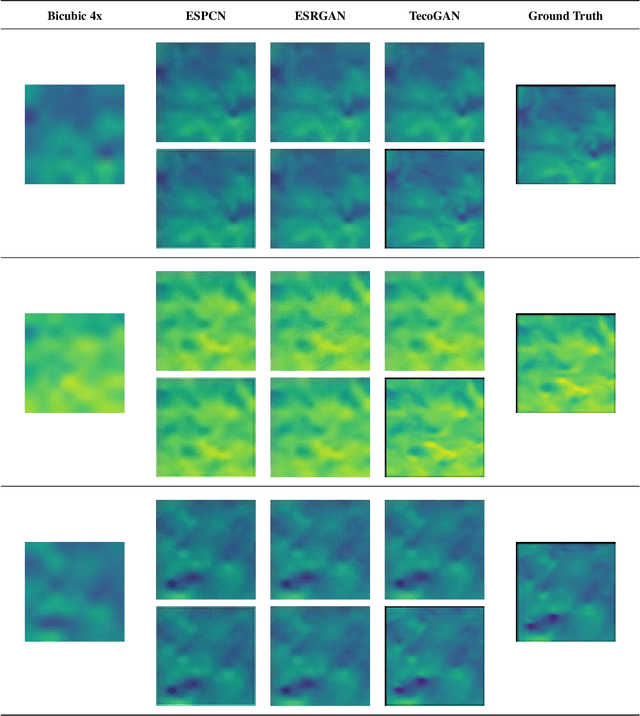
Super-resolution is an innovative technique that upscales the resolution of an image or a video and thus enables us to reconstruct high-fidelity images from low-resolution data. This study performs super-resolution analysis on turbulent flow fields spatially and temporally using various state-of-the-art machine learning techniques like ESPCN, ESRGAN and TecoGAN to reconstruct high-resolution flow fields from low-resolution flow field data, especially keeping in mind the need for low resource consumption and rapid results production/verification. The dataset used for this study is extracted from the 'isotropic 1024 coarse' dataset which is a part of Johns Hopkins Turbulence Databases (JHTDB). We have utilized pre-trained models and fine tuned them to our needs, so as to minimize the computational resources and the time required for the implementation of the super-resolution models. The advantages presented by this method far exceed the expectations and the outcomes of regular single structure models. The results obtained through these models are then compared using MSE, PSNR, SAM, VIF and SCC metrics in order to evaluate the upscaled results, find the balance between computational power and output quality, and then identify the most accurate and efficient model for spatial and temporal super-resolution of turbulent flow fields.