 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Mixed Sentiment Analysis Using Machine Learning and Neural Network Approaches
Aug 09, 2018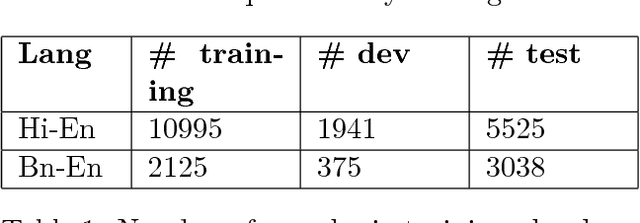

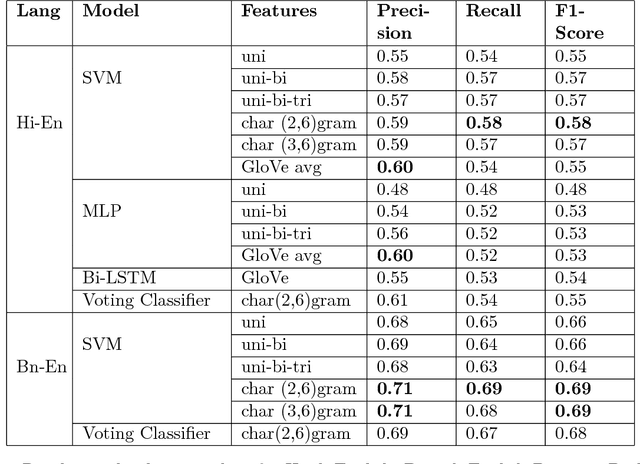
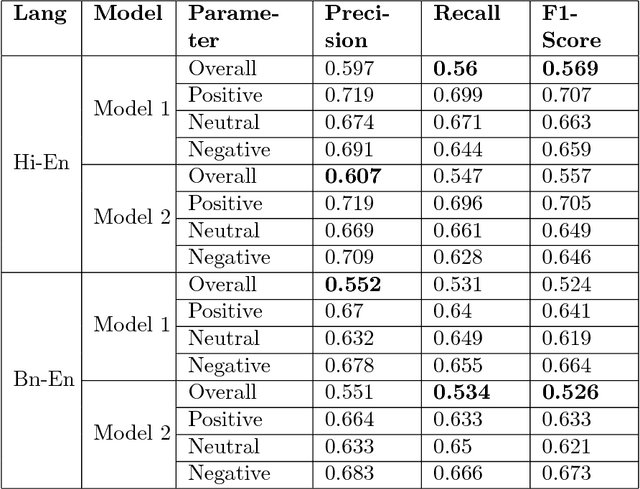
Sentiment Analysis for Indian Languages (SAIL)-Code Mixed tools contest aimed at identifying the sentence level sentiment polarity of the code-mixed dataset of Indian languages pairs (Hi-En, Ben-Hi-En). Hi-En dataset is henceforth referred to as HI-EN and Ben-Hi-En dataset as BN-EN respectively. For this, we submitted four models for sentiment analysis of code-mixed HI-EN and BN-EN datasets. The first model was an ensemble voting classifier consisting of three classifiers - linear SVM, logistic regression and random forests while the second one was a linear SVM. Both the models used TF-IDF feature vectors of character n-grams where n ranged from 2 to 6. We used scikit-learn (sklearn) machine learning library for implementing both the approaches. Run1 was obtained from the voting classifier and Run2 used the linear SVM model for producing the results. Out of the four submitted outputs Run2 outperformed Run1 in both the datasets. We finished first in the contest for both HI-EN with an F-score of 0.569 and BN-EN with an F-score of 0.526.