 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal World Applications of Machine Learning Techniques over Large Mobile Subscriber Datasets
Feb 08, 2015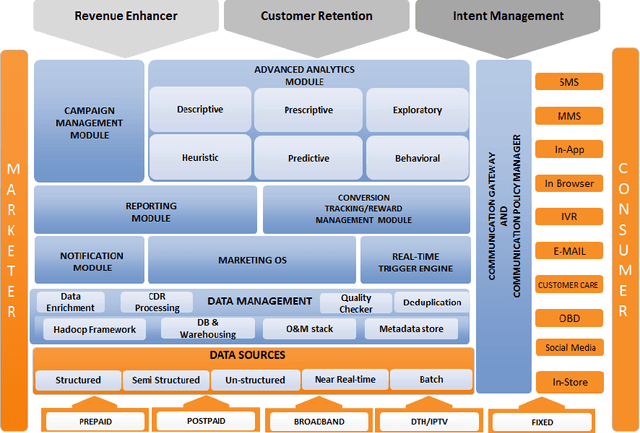
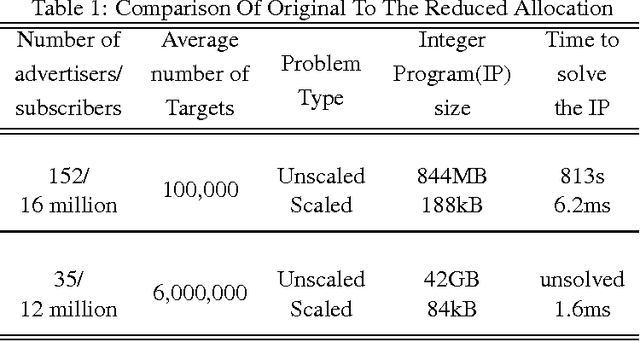

Communication Service Providers (CSPs) are in a unique position to utilize their vast transactional data assets generated from interactions of subscribers with network elements as well as with other subscribers. CSPs could leverage its data assets for a gamut of applications such as service personalization, predictive offer management, loyalty management, revenue forecasting, network capacity planning, product bundle optimization and churn management to gain significant competitive advantage. However, due to the sheer data volume, variety, velocity and veracity of mobile subscriber datasets, sophisticated data analytics techniques and frameworks are necessary to derive actionable insights in a useable timeframe. In this paper, we describe our journey from a relational database management system (RDBMS) based campaign management solution which allowed data scientists and marketers to use hand-written rules for service personalization and targeted promotions to a distributed Big Data Analytics platform, capable of performing large scale machine learning and data mining to deliver real time service personalization, predictive modelling and product optimization. Our work involves a careful blend of technology, processes and best practices, which facilitate man-machine collaboration and continuous experimentation to derive measurable economic value from data. Our platform has a reach of more than 500 million mobile subscribers worldwide, delivering over 1 billion personalized recommendations annually, processing a total data volume of 64 Petabytes, corresponding to 8.5 trillion events.
Improving Collaborative Filtering based Recommenders using Topic Modelling
Feb 25, 2014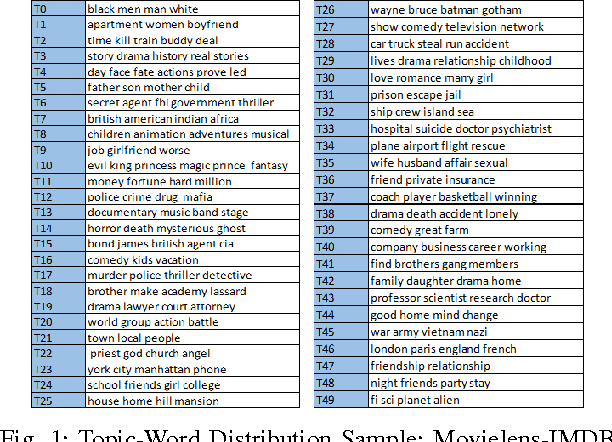
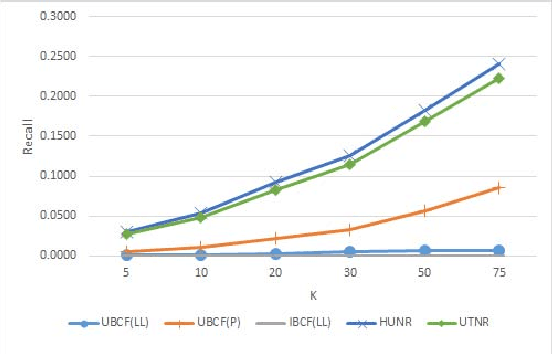
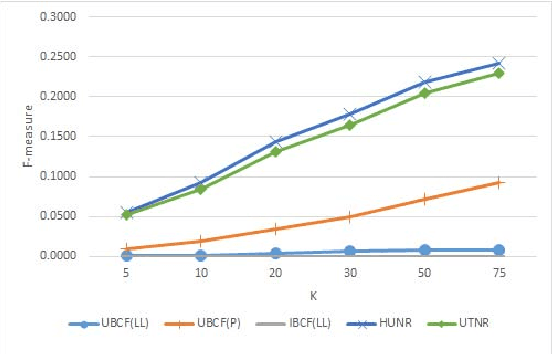
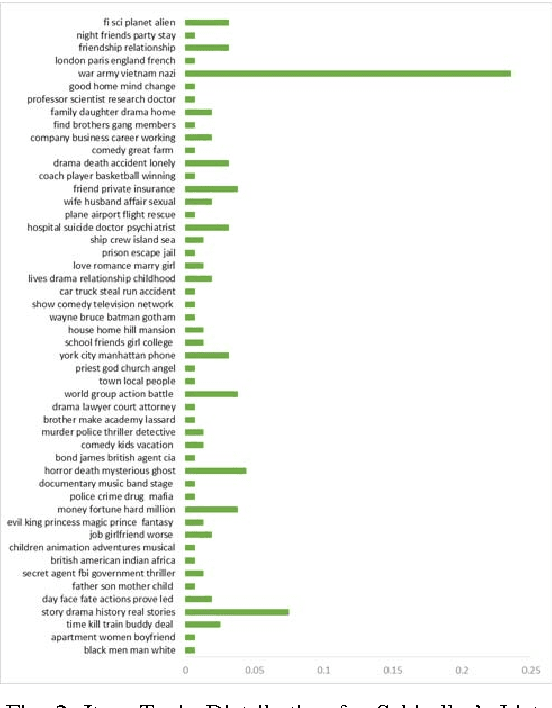
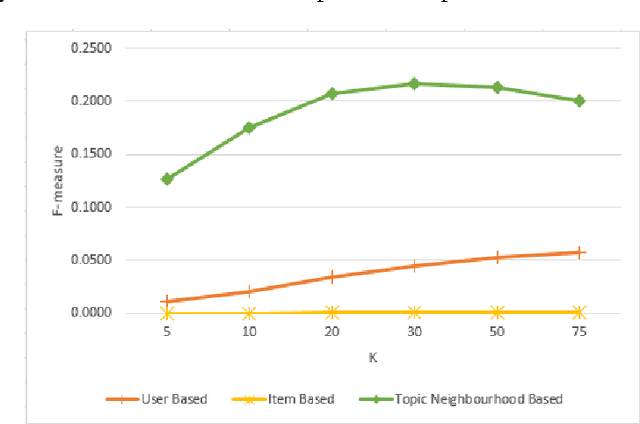
Standard Collaborative Filtering (CF) algorithms make use of interactions between users and items in the form of implicit or explicit ratings alone for generating recommendations. Similarity among users or items is calculated purely based on rating overlap in this case,without considering explicit properties of users or items involved, limiting their applicability in domains with very sparse rating spaces. In many domains such as movies, news or electronic commerce recommenders, considerable contextual data in text form describing item properties is available along with the rating data, which could be utilized to improve recommendation quality.In this paper, we propose a novel approach to improve standard CF based recommenders by utilizing latent Dirichlet allocation (LDA) to learn latent properties of items, expressed in terms of topic proportions, derived from their textual description. We infer user's topic preferences or persona in the same latent space,based on her historical ratings. While computing similarity between users, we make use of a combined similarity measure involving rating overlap as well as similarity in the latent topic space. This approach alleviates sparsity problem as it allows calculation of similarity between users even if they have not rated any items in common. Our experiments on multiple public datasets indicate that the proposed hybrid approach significantly outperforms standard user Based and item Based CF recommenders in terms of classification accuracy metrics such as precision, recall and f-measure.