 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic Image Reconstruction from Hybrid Intensity and Event based Sensor
Oct 25, 2018

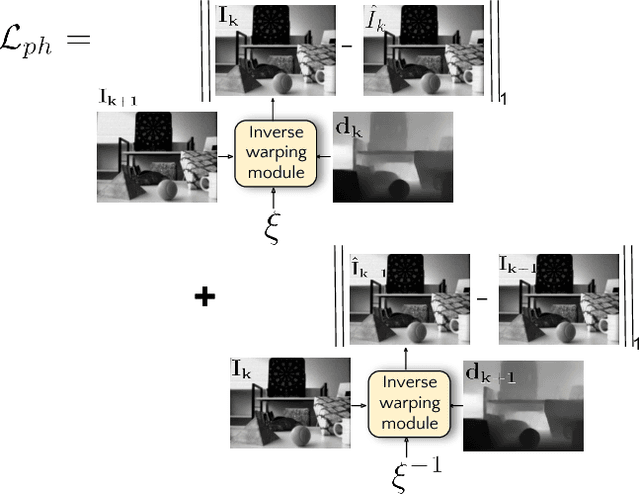
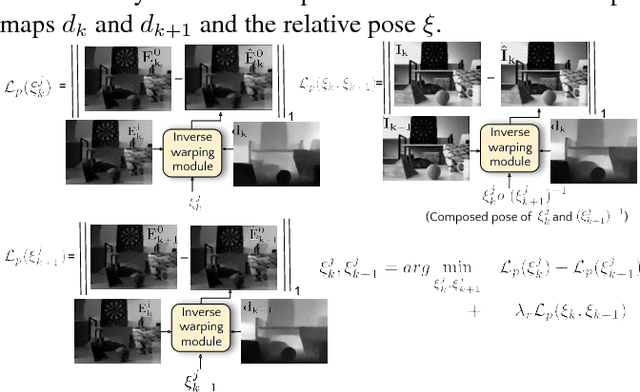
Event sensors output a stream of asynchronous brightness changes (called "events") at a very high temporal rate. Since, these "events" cannot be used directly for traditional computer vision algorithms, many researchers attempted at recovering the intensity information from this stream of events. Although the results are promising, they lack the texture and the consistency of natural videos. We propose to reconstruct photorealistic intensity images from a hybrid sensor consisting of a low frame rate conventional camera along with the event sensor. DAVIS is a commercially available hybrid sensor which bundles the conventional image sensor and the event sensor into a single hardware. To accomplish our task, we use the low frame rate intensity images and warp them to the temporally dense locations of the event data by estimating a spatially dense scene depth and temporally dense sensor ego-motion. We thereby obtain temporally dense photorealisitic images which would have been very difficult by using only either the event sensor or the conventional low frame-rate image sensor. In addition, we also obtain spatio-temporally dense scene flow as a by product of estimating spatially dense depth map and temporally dense sensor ego-motion.
Data Driven Coded Aperture Design for Depth Recovery
Jun 01, 2017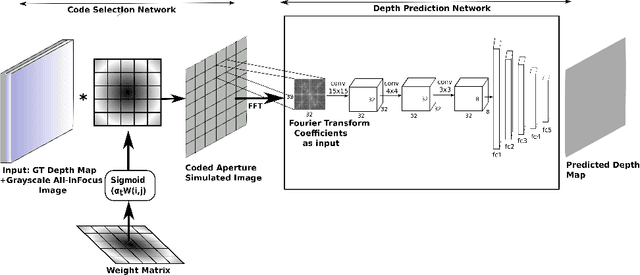
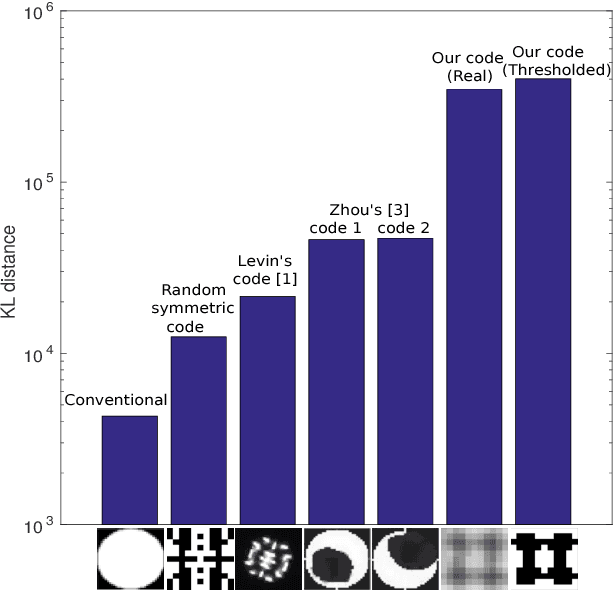
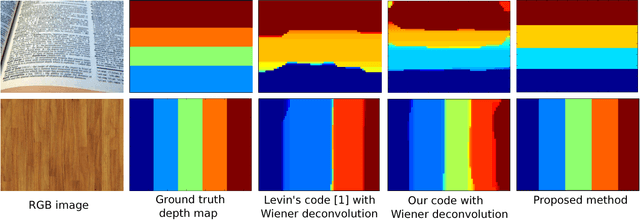

Inserting a patterned occluder at the aperture of a camera lens has been shown to improve the recovery of depth map and all-focus image compared to a fully open aperture. However, design of the aperture pattern plays a very critical role. Previous approaches for designing aperture codes make simple assumptions on image distributions to obtain metrics for evaluating aperture codes. However, real images may not follow those assumptions and hence the designed code may not be optimal for them. To address this drawback we propose a data driven approach for learning the optimal aperture pattern to recover depth map from a single coded image. We propose a two stage architecture where, in the first stage we simulate coded aperture images from a training dataset of all-focus images and depth maps and in the second stage we recover the depth map using a deep neural network. We demonstrate that our learned aperture code performs better than previously designed codes even on code design metrics proposed by previous approaches.