 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdUE: Improving uncertainty estimation head for LoRA adapters in LLMs
May 21, 2025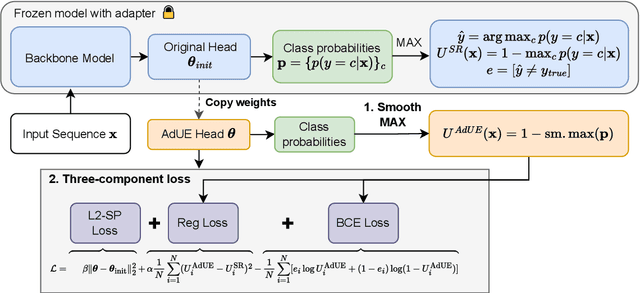
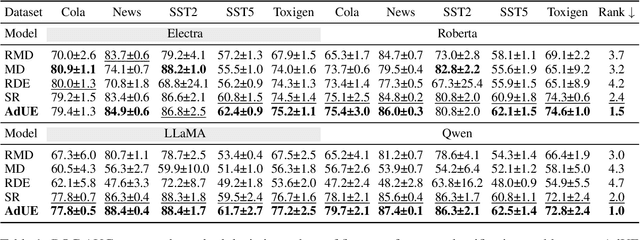

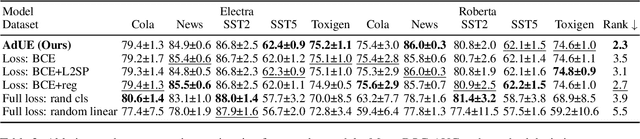
Uncertainty estimation remains a critical challenge in adapting pre-trained language models to classification tasks, particularly under parameter-efficient fine-tuning approaches such as adapters. We introduce AdUE1, an efficient post-hoc uncertainty estimation (UE) method, to enhance softmax-based estimates. Our approach (1) uses a differentiable approximation of the maximum function and (2) applies additional regularization through L2-SP, anchoring the fine-tuned head weights and regularizing the model. Evaluations on five NLP classification datasets across four language models (RoBERTa, ELECTRA, LLaMA-2, Qwen) demonstrate that our method consistently outperforms established baselines such as Mahalanobis distance and softmax response. Our approach is lightweight (no base-model changes) and produces better-calibrated confidence.
Diversity-Aware Ensembling of Language Models Based on Topological Data Analysis
Feb 22, 2024



Ensembles are important tools for improving the performance of machine learning models. In cases related to natural language processing, ensembles boost the performance of a method due to multiple large models available in open source. However, existing approaches mostly rely on simple averaging of predictions by ensembles with equal weights for each model, ignoring differences in the quality and conformity of models. We propose to estimate weights for ensembles of NLP models using not only knowledge of their individual performance but also their similarity to each other. By adopting distance measures based on Topological Data Analysis (TDA), we improve our ensemble. The quality improves for both text classification accuracy and relevant uncertainty estimation.