 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTifying Sinhala -- A Comprehensive Analysis of Pre-trained Language Models for Sinhala Text Classification
Aug 17, 2022
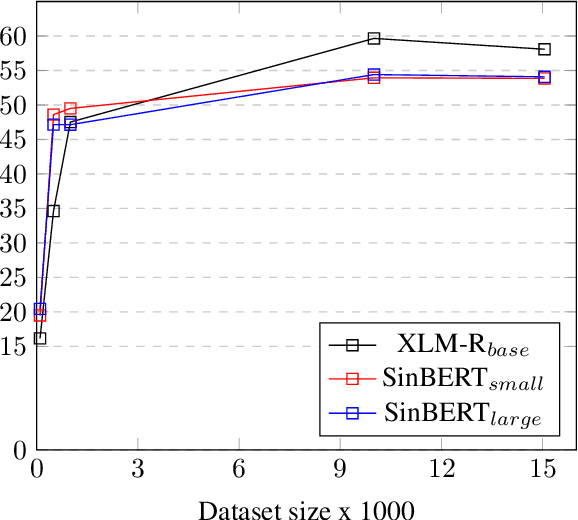
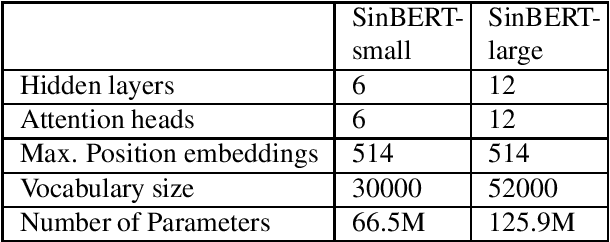
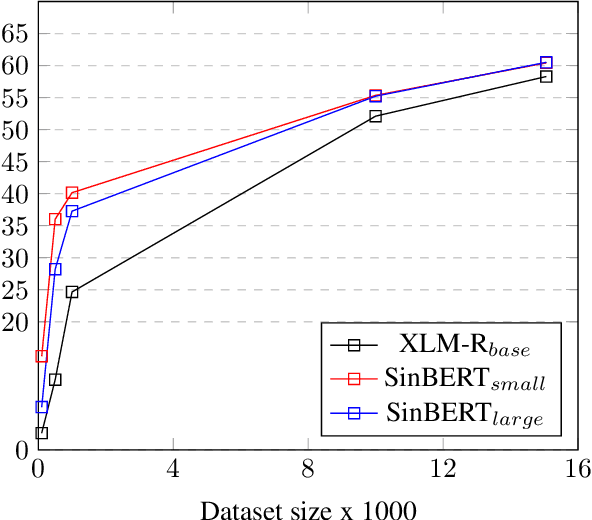
This research provides the first comprehensive analysis of the performance of pre-trained language models for Sinhala text classification. We test on a set of different Sinhala text classification tasks and our analysis shows that out of the pre-trained multilingual models that include Sinhala (XLM-R, LaBSE, and LASER), XLM-R is the best model by far for Sinhala text classification. We also pre-train two RoBERTa-based monolingual Sinhala models, which are far superior to the existing pre-trained language models for Sinhala. We show that when fine-tuned, these pre-trained language models set a very strong baseline for Sinhala text classification and are robust in situations where labeled data is insufficient for fine-tuning. We further provide a set of recommendations for using pre-trained models for Sinhala text classification. We also introduce new annotated datasets useful for future research in Sinhala text classification and publicly release our pre-trained models.
Dual-State Capsule Networks for Text Classification
Sep 10, 2021


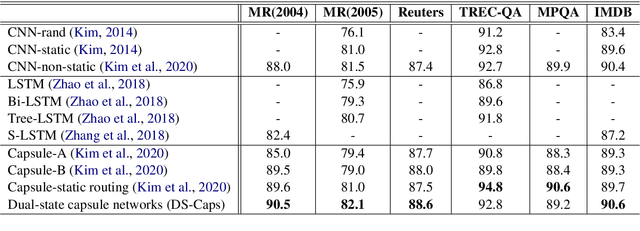
Text classification systems based on contextual embeddings are not viable options for many of the low resource languages. On the other hand, recently introduced capsule networks have shown performance in par with these text classification models. Thus, they could be considered as a viable alternative for text classification for languages that do not have pre-trained contextual embedding models. However, current capsule networks depend upon spatial patterns without considering the sequential features of the text. They are also sub-optimal in capturing the context-level information in longer sequences. This paper presents a novel Dual-State Capsule (DS-Caps) network-based technique for text classification, which is optimized to mitigate these issues. Two varieties of states, namely sentence-level and word-level, are integrated with capsule layers to capture deeper context-level information for language modeling. The dynamic routing process among capsules was also optimized using the context-level information obtained through sentence-level states. The DS-Caps networks outperform the existing capsule network architectures for multiple datasets, particularly for tasks with longer sequences of text. We also demonstrate the superiority of DS-Caps in text classification for a low resource language.
Sentiment Analysis for Sinhala Language using Deep Learning Techniques
Nov 14, 2020

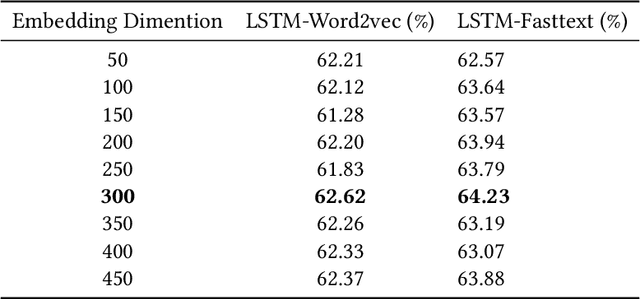

Due to the high impact of the fast-evolving fields of machine learning and deep learning, Natural Language Processing (NLP) tasks have further obtained comprehensive performances for highly resourced languages such as English and Chinese. However Sinhala, which is an under-resourced language with a rich morphology, has not experienced these advancements. For sentiment analysis, there exists only two previous research with deep learning approaches, which focused only on document-level sentiment analysis for the binary case. They experimented with only three types of deep learning models. In contrast, this paper presents a much comprehensive study on the use of standard sequence models such as RNN, LSTM, Bi-LSTM, as well as more recent state-of-the-art models such as hierarchical attention hybrid neural networks, and capsule networks. Classification is done at document-level but with more granularity by considering POSITIVE, NEGATIVE, NEUTRAL, and CONFLICT classes. A data set of 15059 Sinhala news comments, annotated with these four classes and a corpus consists of 9.48 million tokens are publicly released. This is the largest sentiment annotated data set for Sinhala so far.