 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTifying Sinhala -- A Comprehensive Analysis of Pre-trained Language Models for Sinhala Text Classification
Paper and Code

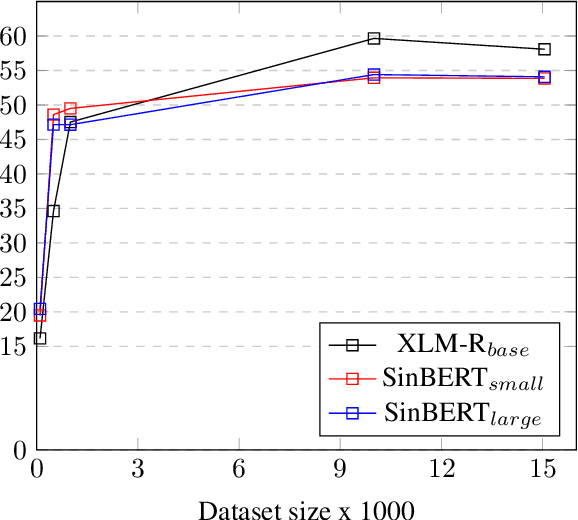
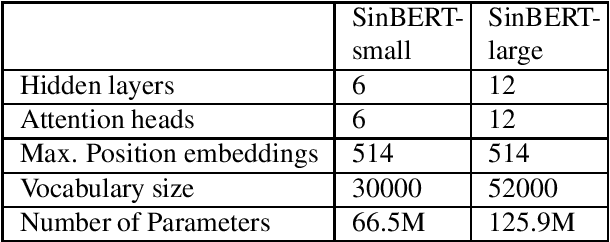
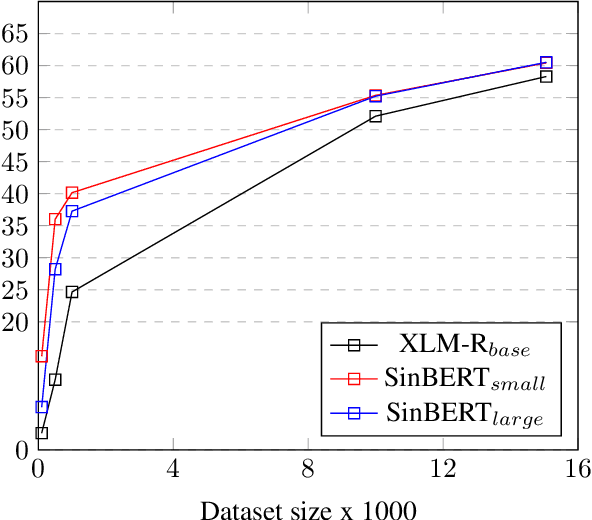
This research provides the first comprehensive analysis of the performance of pre-trained language models for Sinhala text classification. We test on a set of different Sinhala text classification tasks and our analysis shows that out of the pre-trained multilingual models that include Sinhala (XLM-R, LaBSE, and LASER), XLM-R is the best model by far for Sinhala text classification. We also pre-train two RoBERTa-based monolingual Sinhala models, which are far superior to the existing pre-trained language models for Sinhala. We show that when fine-tuned, these pre-trained language models set a very strong baseline for Sinhala text classification and are robust in situations where labeled data is insufficient for fine-tuning. We further provide a set of recommendations for using pre-trained models for Sinhala text classification. We also introduce new annotated datasets useful for future research in Sinhala text classification and publicly release our pre-trained models.