 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating hypersonic reentry simulations using deep learning-based hybridization (with guarantees)
Sep 30, 2022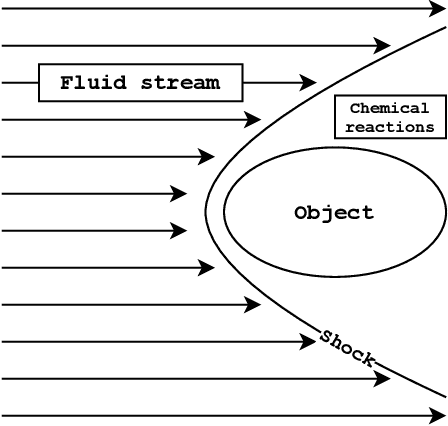

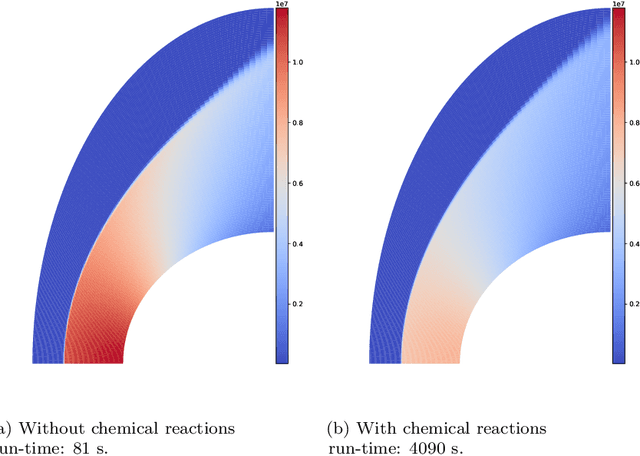
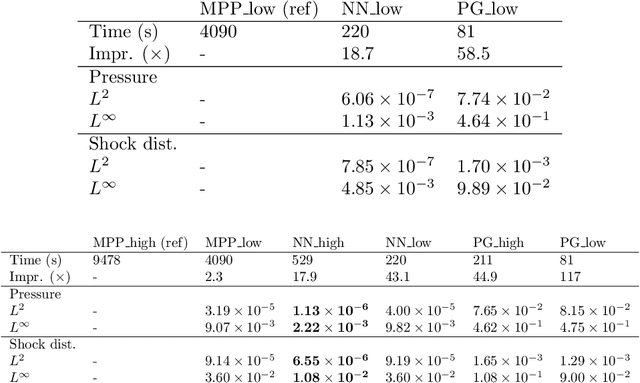
In this paper, we are interested in the acceleration of numerical simulations. We focus on a hypersonic planetary reentry problem whose simulation involves coupling fluid dynamics and chemical reactions. Simulating chemical reactions takes most of the computational time but, on the other hand, cannot be avoided to obtain accurate predictions. We face a trade-off between cost-efficiency and accuracy: the simulation code has to be sufficiently efficient to be used in an operational context but accurate enough to predict the phenomenon faithfully. To tackle this trade-off, we design a hybrid simulation code coupling a traditional fluid dynamic solver with a neural network approximating the chemical reactions. We rely on their power in terms of accuracy and dimension reduction when applied in a big data context and on their efficiency stemming from their matrix-vector structure to achieve important acceleration factors ($\times 10$ to $\times 18.6$). This paper aims to explain how we design such cost-effective hybrid simulation codes in practice. Above all, we describe methodologies to ensure accuracy guarantees, allowing us to go beyond traditional surrogate modeling and to use these codes as references.
Goal-Oriented Sensitivity Analysis of Hyperparameters in Deep Learning
Jul 13, 2022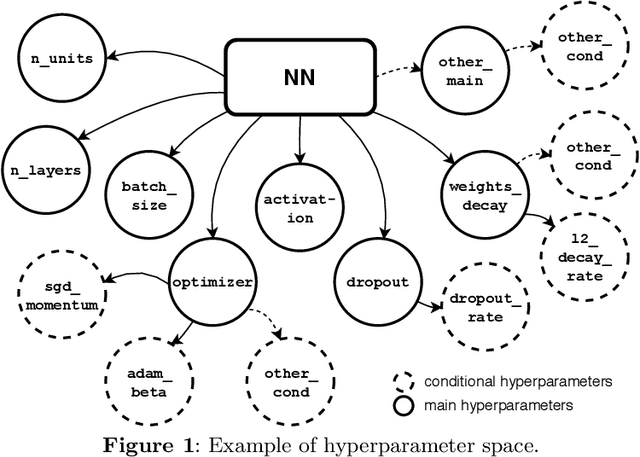
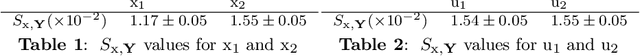
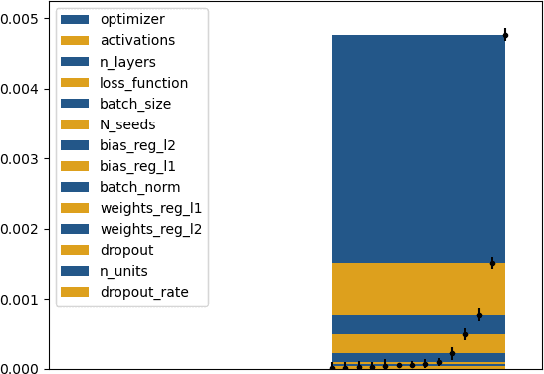
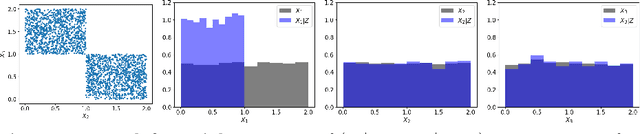
Tackling new machine learning problems with neural networks always means optimizing numerous hyperparameters that define their structure and strongly impact their performances. In this work, we study the use of goal-oriented sensitivity analysis, based on the Hilbert-Schmidt Independence Criterion (HSIC), for hyperparameter analysis and optimization. Hyperparameters live in spaces that are often complex and awkward. They can be of different natures (categorical, discrete, boolean, continuous), interact, and have inter-dependencies. All this makes it non-trivial to perform classical sensitivity analysis. We alleviate these difficulties to obtain a robust analysis index that is able to quantify hyperparameters' relative impact on a neural network's final error. This valuable tool allows us to better understand hyperparameters and to make hyperparameter optimization more interpretable. We illustrate the benefits of this knowledge in the context of hyperparameter optimization and derive an HSIC-based optimization algorithm that we apply on MNIST and Cifar, classical machine learning data sets, but also on the approximation of Runge function and Bateman equations solution, of interest for scientific machine learning. This method yields neural networks that are both competitive and cost-effective.