 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Based Samples Weighting for Supervised Deep Learning
Jan 28, 2021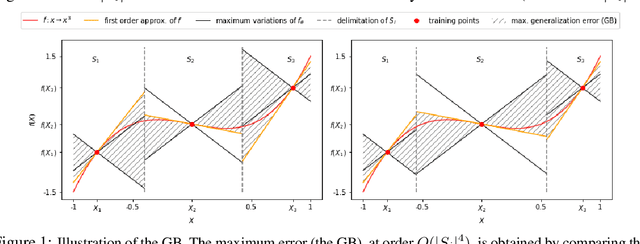
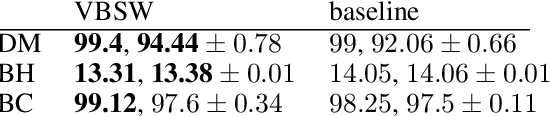
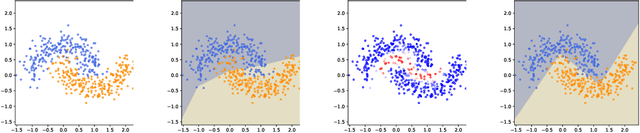

In the context of supervised learning of a function by a Neural Network (NN), we claim and empirically justify that a NN yields better results when the distribution of the data set focuses on regions where the function to learn is steeper. We first traduce this assumption in a mathematically workable way using Taylor expansion. Then, theoretical derivations allow to construct a methodology that we call Variance Based Samples Weighting (VBSW). VBSW uses local variance of the labels to weight the training points. This methodology is general, scalable, cost effective, and significantly increases the performances of a large class of NNs for various classification and regression tasks on image, text and multivariate data. We highlight its benefits with experiments involving NNs from shallow linear NN to Resnet or Bert.
A Taylor Based Sampling Scheme for Machine Learning in Computational Physics
Jan 28, 2021
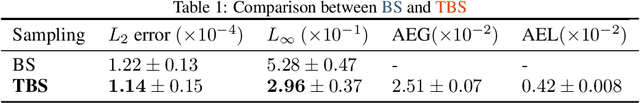
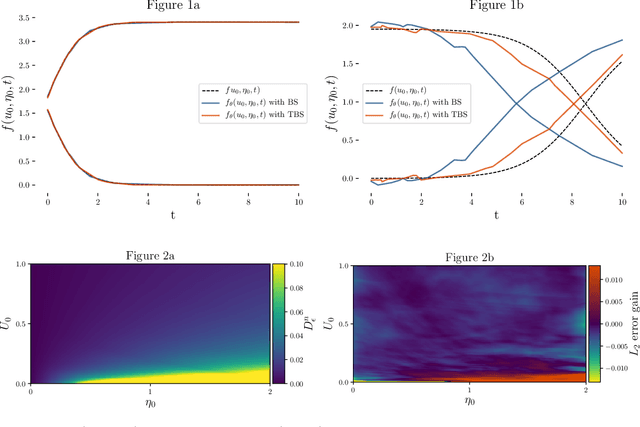
Machine Learning (ML) is increasingly used to construct surrogate models for physical simulations. We take advantage of the ability to generate data using numerical simulations programs to train ML models better and achieve accuracy gain with no performance cost. We elaborate a new data sampling scheme based on Taylor approximation to reduce the error of a Deep Neural Network (DNN) when learning the solution of an ordinary differential equations (ODE) system.