Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Curriculum Reinforcement Learning for End-to-End Driving
Mar 16, 2021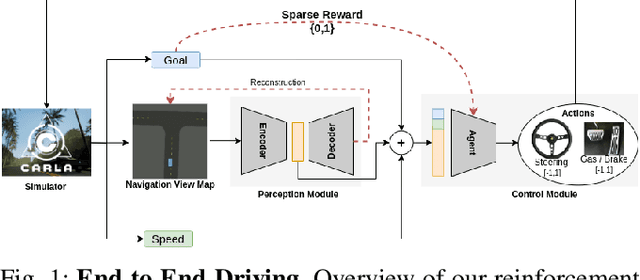
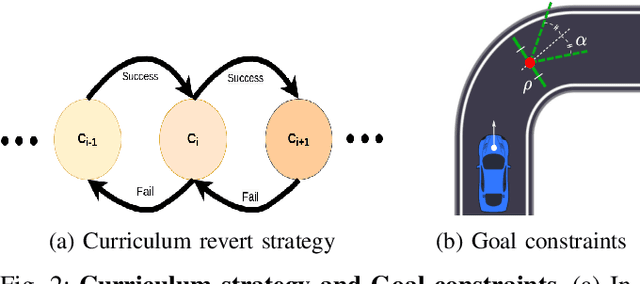
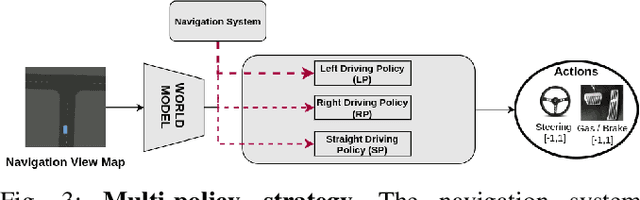
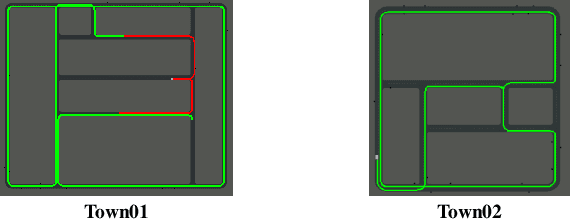
Deep reinforcement Learning for end-to-end driving is limited by the need of complex reward engineering. Sparse rewards can circumvent this challenge but suffers from long training time and leads to sub-optimal policy. In this work, we explore driving using only goal conditioned sparse rewards and propose a curriculum learning approach for end to end driving using only navigation view maps that benefit from small virtual-to-real domain gap. To address the complexity of multiple driving policies, we learn concurrent individual policies which are selected at inference by a navigation system. We demonstrate the ability of our proposal to generalize on unseen road layout, and to drive longer than in the training.
* 6 pages, 8 figures
Via