 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Quantization and its Impact on Output Performance
May 19, 2026Recent advancements in large language models (LLMs) have shown their remarkable capacities in many NLP tasks. However, their substantial size often presents challenges for deployment. This necessitates efficient techniques for model compression, with quantization emerging as a prominent solution. Despite its benefits, the exact impact of quantization (from 2- to 6-bit) on the performance and accuracy of LLMs remains an active area of research. This paper investigates the performance of eight LLMs at various quantization levels, focusing on tasks such as MMLU-Pro for knowledge processing and reasoning, CRUXEval for code comprehension, and MuSR for reading comprehension. Our results show a consistent trend where higher precision (e.g., 8-bit Q8\_0) yields improved performance, albeit with diminishing returns. Aggressive quantization (e.g., 2-bit Q2\_K) usually retains acceptable accuracy, though some models show a substantial loss in performance. Our findings indicate that while lower bit precision generally reduces performance, the impact varies across models and tasks. Larger models show greater resilience to aggressive quantization, but can still undergo significant drops at lower precision levels. Mid-sized models in the 7-9 billion parameter range strike an optimal balance between efficiency and resource usage. Such results provide insights into the trade-offs between model size, quantization, and performance.
ATLAS: Article Tracking, Linking, and Analysis of Swedish Encyclopedias
May 04, 2026The digitization of old encyclopedias represents an important step to improve access to historically structured knowledge. Often, however, this process does not go beyond an optical character recognition, leaving all the underlying structure unexploited. In addition, many encyclopedias had multiple editions reflecting the evolution of knowledge. The lack of structure in the raw text makes it difficult to track changes across these editions. In this work, we built a pipeline to restore the text structure, where we extract the headwords and identify entries; categorize the entities; match entries across editions; and link entries to a Wikidata item. We applied this pipeline to the four major editions of \textit{Nordisk familjebok}, an authoritative Swedish encyclopedia published between 1876 and 1951. We could extract the headwords with an F1 score of 97.8\% and we obtained an F1 score of 93.4\% on the headword classification. On a small-scale evaluation, we reached a 93\% precision on the cross-edition matching, 85\% precision and 16.5\% recall on the Wikidata linking. This shows that an automated approach to digitized historical knowledge is possible. This should facilitate the preservation of general knowledge and the understanding of knowledge transmission. The datasets and programs are available online.
* 11 pages, 5 figures
EDDA-Coordinata: An Annotated Dataset of Historical Geographic Coordinates
Feb 27, 2026This paper introduces a dataset of enriched geographic coordinates retrieved from Diderot and d'Alembert's eighteenth-century Encyclopedie. Automatically recovering geographic coordinates from historical texts is a complex task, as they are expressed in a variety of ways and with varying levels of precision. To improve retrieval of coordinates from similar digitized early modern texts, we have created a gold standard dataset, trained models, published the resulting inferred and normalized coordinate data, and experimented applying these models to new texts. From 74,000 total articles in each of the digitized versions of the Encyclopedie from ARTFL and ENCCRE, we examined 15,278 geographical entries, manually identifying 4,798 containing coordinates, and 10,480 with descriptive but non-numerical references. Leveraging our gold standard annotations, we trained transformer-based models to retrieve and normalize coordinates. The pipeline presented here combines a classifier to identify coordinate-bearing entries and a second model for retrieval, tested across encoder-decoder and decoder architectures. Cross-validation yielded an 86% EM score. On an out-of-domain eighteenth-century Trevoux dictionary (also in French), our fine-tuned model had a 61% EM score, while for the nineteenth-century, 7th edition of the Encyclopaedia Britannica in English, the EM was 77%. These findings highlight the gold standard dataset's usefulness as training data, and our two-step method's cross-lingual, cross-domain generalizability.
Matching and Linking Entries in Historical Swedish Encyclopedias
Jul 01, 2025
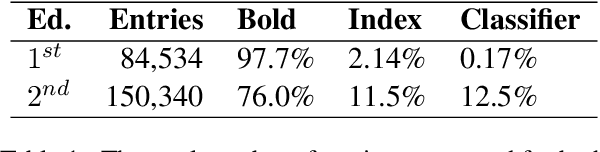

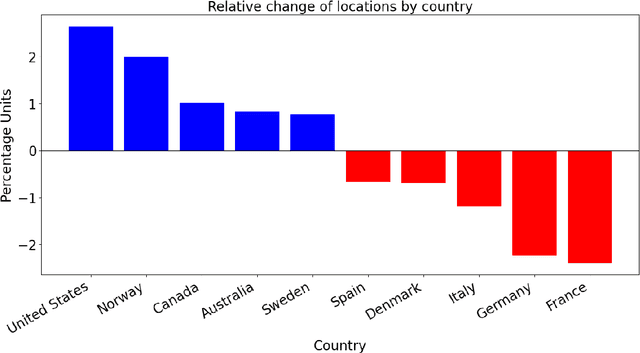
The \textit{Nordisk familjebok} is a Swedish encyclopedia from the 19th and 20th centuries. It was written by a team of experts and aimed to be an intellectual reference, stressing precision and accuracy. This encyclopedia had four main editions remarkable by their size, ranging from 20 to 38 volumes. As a consequence, the \textit{Nordisk familjebok} had a considerable influence in universities, schools, the media, and society overall. As new editions were released, the selection of entries and their content evolved, reflecting intellectual changes in Sweden. In this paper, we used digitized versions from \textit{Project Runeberg}. We first resegmented the raw text into entries and matched pairs of entries between the first and second editions using semantic sentence embeddings. We then extracted the geographical entries from both editions using a transformer-based classifier and linked them to Wikidata. This enabled us to identify geographic trends and possible shifts between the first and second editions, written between 1876-1899 and 1904-1926, respectively. Interpreting the results, we observe a small but significant shift in geographic focus away from Europe and towards North America, Africa, Asia, Australia, and northern Scandinavia from the first to the second edition, confirming the influence of the First World War and the rise of new powers. The code and data are available on GitHub at https://github.com/sibbo/nordisk-familjebok.
* 10 pages, 3 figures
Mapping the Past: Geographically Linking an Early 20th Century Swedish Encyclopedia with Wikidata
Jun 25, 2024In this paper, we describe the extraction of all the location entries from a prominent Swedish encyclopedia from the early 20th century, the \textit{Nordisk Familjebok} `Nordic Family Book.' We focused on the second edition called \textit{Uggleupplagan}, which comprises 38 volumes and over 182,000 articles. This makes it one of the most extensive Swedish encyclopedias. Using a classifier, we first determined the category of the entries. We found that approximately 22 percent of them were locations. We applied a named entity recognition to these entries and we linked them to Wikidata. Wikidata enabled us to extract their precise geographic locations resulting in almost 18,000 valid coordinates. We then analyzed the distribution of these locations and the entry selection process. It showed a higher density within Sweden, Germany, and the United Kingdom. The paper sheds light on the selection and representation of geographic information in the \textit{Nordisk Familjebok}, providing insights into historical and societal perspectives. It also paves the way for future investigations into entry selection in different time periods and comparative analyses among various encyclopedias.
* 9 pages, 3 figures
Linking Named Entities in Diderot's \textit{Encyclopédie} to Wikidata
Jun 05, 2024



Diderot's \textit{Encyclop\'edie} is a reference work from XVIIIth century in Europe that aimed at collecting the knowledge of its era. \textit{Wikipedia} has the same ambition with a much greater scope. However, the lack of digital connection between the two encyclopedias may hinder their comparison and the study of how knowledge has evolved. A key element of \textit{Wikipedia} is Wikidata that backs the articles with a graph of structured data. In this paper, we describe the annotation of more than 10,300 of the \textit{Encyclop\'edie} entries with Wikidata identifiers enabling us to connect these entries to the graph. We considered geographic and human entities. The \textit{Encyclop\'edie} does not contain biographic entries as they mostly appear as subentries of locations. We extracted all the geographic entries and we completely annotated all the entries containing a description of human entities. This represents more than 2,600 links referring to locations or human entities. In addition, we annotated more than 9,500 entries having a geographic content only. We describe the annotation process as well as application examples. This resource is available at https://github.com/pnugues/encyclopedie_1751
* 6 pages, 3 figures
Object Detector Differences when using Synthetic and Real Training Data
Dec 01, 2023To train well-performing generalizing neural networks, sufficiently large and diverse datasets are needed. Collecting data while adhering to privacy legislation becomes increasingly difficult and annotating these large datasets is both a resource-heavy and time-consuming task. An approach to overcome these difficulties is to use synthetic data since it is inherently scalable and can be automatically annotated. However, how training on synthetic data affects the layers of a neural network is still unclear. In this paper, we train the YOLOv3 object detector on real and synthetic images from city environments. We perform a similarity analysis using Centered Kernel Alignment (CKA) to explore the effects of training on synthetic data on a layer-wise basis. The analysis captures the architecture of the detector while showing both different and similar patterns between different models. With this similarity analysis we want to give insights on how training synthetic data affects each layer and to give a better understanding of the inner workings of complex neural networks. The results show that the largest similarity between a detector trained on real data and a detector trained on synthetic data was in the early layers, and the largest difference was in the head part. The results also show that no major difference in performance or similarity could be seen between frozen and unfrozen backbone.
* 27 pages. The Version of Record of this article is published in Springer Nature Computer Science 2023, and is available online at https://doi.org/10.1007/s42979-023-01704-5
EasyNER: A Customizable Easy-to-Use Pipeline for Deep Learning- and Dictionary-based Named Entity Recognition from Medical Text
Apr 16, 2023



Medical research generates a large number of publications with the PubMed database already containing >35 million research articles. Integration of the knowledge scattered across this large body of literature could provide key insights into physiological mechanisms and disease processes leading to novel medical interventions. However, it is a great challenge for researchers to utilize this information in full since the scale and complexity of the data greatly surpasses human processing abilities. This becomes especially problematic in cases of extreme urgency like the COVID-19 pandemic. Automated text mining can help extract and connect information from the large body of medical research articles. The first step in text mining is typically the identification of specific classes of keywords (e.g., all protein or disease names), so called Named Entity Recognition (NER). Here we present an end-to-end pipeline for NER of typical entities found in medical research articles, including diseases, cells, chemicals, genes/proteins, and species. The pipeline can access and process large medical research article collections (PubMed, CORD-19) or raw text and incorporates a series of deep learning models fine-tuned on the HUNER corpora collection. In addition, the pipeline can perform dictionary-based NER related to COVID-19 and other medical topics. Users can also load their own NER models and dictionaries to include additional entities. The output consists of publication-ready ranked lists and graphs of detected entities and files containing the annotated texts. An associated script allows rapid inspection of the results for specific entities of interest. As model use cases, the pipeline was deployed on two collections of autophagy-related abstracts from PubMed and on the CORD19 dataset, a collection of 764 398 research article abstracts related to COVID-19.
Connecting a French Dictionary from the Beginning of the 20th Century to Wikidata
Jun 26, 2022

The \textit{Petit Larousse illustr\'e} is a French dictionary first published in 1905. Its division in two main parts on language and on history and geography corresponds to a major milestone in French lexicography as well as a repository of general knowledge from this period. Although the value of many entries from 1905 remains intact, some descriptions now have a dimension that is more historical than contemporary. They are nonetheless significant to analyze and understand cultural representations from this time. A comparison with more recent information or a verification of these entries would require a tedious manual work. In this paper, we describe a new lexical resource, where we connected all the dictionary entries of the history and geography part to current data sources. For this, we linked each of these entries to a wikidata identifier. Using the wikidata links, we can automate more easily the identification, comparison, and verification of historically-situated representations. We give a few examples on how to process wikidata identifiers and we carried out a small analysis of the entities described in the dictionary to outline possible applications. The resource, i.e. the annotation of 20,245 dictionary entries with wikidata links, is available from GitHub url{https://github.com/pnugues/petit_larousse_1905/
Overview of the Ugglan Entity Discovery and Linking System
Mar 13, 2019



Ugglan is a system designed to discover named entities and link them to unique identifiers in a knowledge base. It is based on a combination of a name and nominal dictionary derived from Wikipedia and Wikidata, a named entity recognition module (NER) using fixed ordinally-forgetting encoding (FOFE) trained on the TAC EDL data from 2014-2016, a candidate generation module from the Wikipedia link graph across multiple editions, a PageRank link and cooccurrence graph disambiguator, and finally a reranker trained on the TAC EDL 2015-2016 data.