 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Measuring Logical Compliance of Predictive Models
Jun 18, 2026Machine learning models are predominantly evaluated through predictive performance metrics such as ranking quality, prediction error, or classification accuracy. While these metrics effectively quantify how closely predictions match the ground truth, they do not assess whether model outputs respect predefined logical or domain-specific constraints. In high-stakes applications, including healthcare, finance, and autonomous systems, logical consistency can be as critical as predictive accuracy, yet no standard metric captures this dimension. We introduce the Rule Violation Score (RVS), a complementary evaluation metric that quantifies the extent to which a predictive model respects a given set of logical rules, independently of predictive accuracy. RVS treats hard rules (strict constraints) and soft rules (statistical regularities) differently, can be evaluated on any dataset and on any predictive model expressed over a relational vocabulary, and can be computed using SQL queries that are automatically generated for Horn rules. Beyond evaluating models, RVS can also evaluate the logical consistency of training datasets and help identify poorly defined rules. We evaluate RVS on three benchmarks covering knowledge graph link prediction and relational regression, including rule-based, embedding-based, and neuro-symbolic predictive models. Our results demonstrate that two models achieving comparable predictive accuracy can exhibit substantially different levels of logical compliance, revealing differences in model behavior that standard metrics fail to capture.
On Scaling Neurosymbolic Programming through Guided Logical Inference
Jan 30, 2025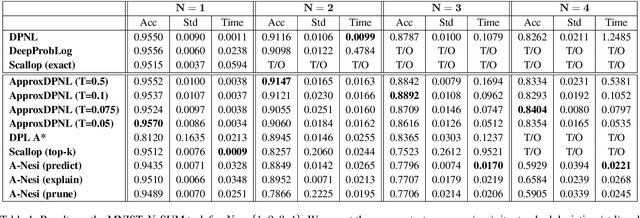

Probabilistic neurosymbolic learning seeks to integrate neural networks with symbolic programming. Many state-of-the-art systems rely on a reduction to the Probabilistic Weighted Model Counting Problem (PWMC), which requires computing a Boolean formula called the logical provenance.However, PWMC is \\#P-hard, and the number of clauses in the logical provenance formula can grow exponentially, creating a major bottleneck that significantly limits the applicability of PNL solutions in practice.We propose a new approach centered around an exact algorithm DPNL, that enables bypassing the computation of the logical provenance.The DPNL approach relies on the principles of an oracle and a recursive DPLL-like decomposition in order to guide and speed up logical inference.Furthermore, we show that this approach can be adapted for approximate reasoning with $\epsilon$ or $(\epsilon, \delta)$ guarantees, called ApproxDPNL.Experiments show significant performance gains.DPNL enables scaling exact inference further, resulting in more accurate models.Further, ApproxDPNL shows potential for advancing the scalability of neurosymbolic programming by incorporating approximations even further, while simultaneously ensuring guarantees for the reasoning process.
Knowledge Enhanced Graph Neural Networks
Mar 27, 2023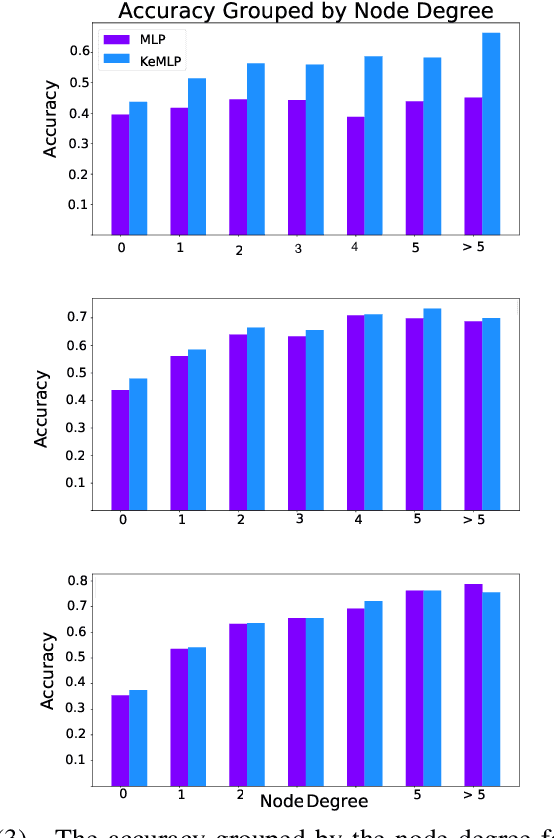
Graph data is omnipresent and has a large variety of applications such as natural science, social networks or semantic web. Though rich in information, graphs are often noisy and incomplete. Therefore, graph completion tasks such as node classification or link prediction have gained attention. On the one hand, neural methods such as graph neural networks have proven to be robust tools for learning rich representations of noisy graphs. On the other hand, symbolic methods enable exact reasoning on graphs. We propose KeGNN, a neuro-symbolic framework for learning on graph data that combines both paradigms and allows for the integration of prior knowledge into a graph neural network model. In essence, KeGNN consists of a graph neural network as a base on which knowledge enhancement layers are stacked with the objective of refining predictions with respect to prior knowledge. We instantiate KeGNN in conjunction with two standard graph neural networks: Graph Convolutional Networks and Graph Attention Networks, and evaluate KeGNN on multiple benchmark datasets for node classification.
Constrained Differentially Private Federated Learning for Low-bandwidth Devices
Feb 27, 2021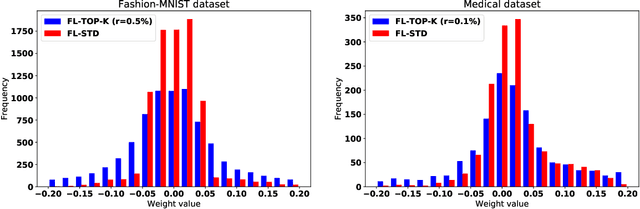
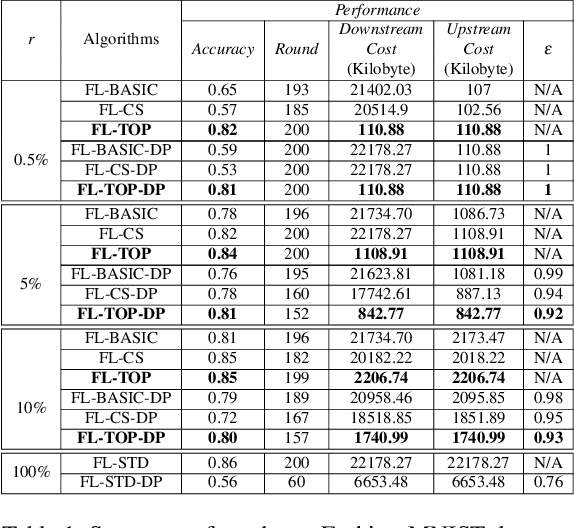
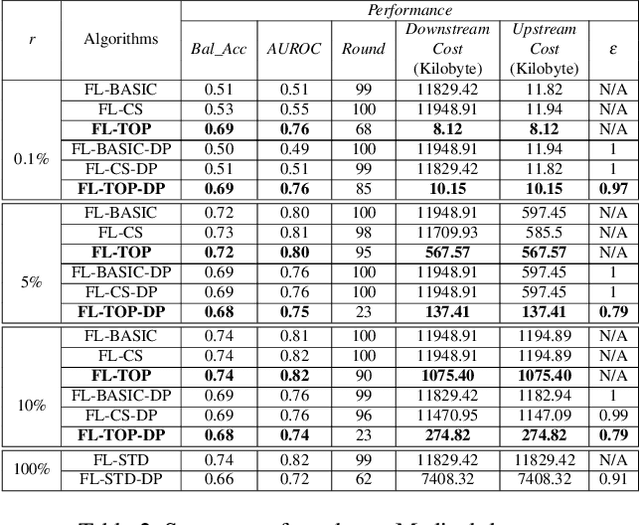

Federated learning becomes a prominent approach when different entities want to learn collaboratively a common model without sharing their training data. However, Federated learning has two main drawbacks. First, it is quite bandwidth inefficient as it involves a lot of message exchanges between the aggregating server and the participating entities. This bandwidth and corresponding processing costs could be prohibitive if the participating entities are, for example, mobile devices. Furthermore, although federated learning improves privacy by not sharing data, recent attacks have shown that it still leaks information about the training data. This paper presents a novel privacy-preserving federated learning scheme. The proposed scheme provides theoretical privacy guarantees, as it is based on Differential Privacy. Furthermore, it optimizes the model accuracy by constraining the model learning phase on few selected weights. Finally, as shown experimentally, it reduces the upstream and downstream bandwidth by up to 99.9% compared to standard federated learning, making it practical for mobile systems.
Compression Boosts Differentially Private Federated Learning
Nov 10, 2020
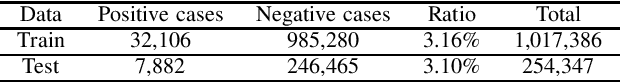
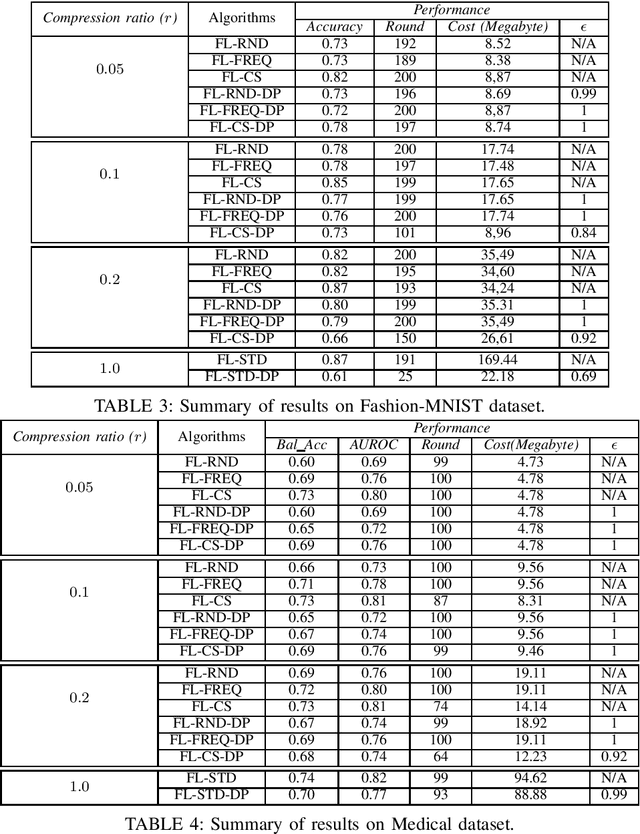

Federated Learning allows distributed entities to train a common model collaboratively without sharing their own data. Although it prevents data collection and aggregation by exchanging only parameter updates, it remains vulnerable to various inference and reconstruction attacks where a malicious entity can learn private information about the participants' training data from the captured gradients. Differential Privacy is used to obtain theoretically sound privacy guarantees against such inference attacks by noising the exchanged update vectors. However, the added noise is proportional to the model size which can be very large with modern neural networks. This can result in poor model quality. In this paper, compressive sensing is used to reduce the model size and hence increase model quality without sacrificing privacy. We show experimentally, using 2 datasets, that our privacy-preserving proposal can reduce the communication costs by up to 95% with only a negligible performance penalty compared to traditional non-private federated learning schemes.