 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew bootstrap tests for categorical time series. A comparative study
Apr 30, 2023The problem of testing the equality of the generating processes of two categorical time series is addressed in this work. To this aim, we propose three tests relying on a dissimilarity measure between categorical processes. Particular versions of these tests are constructed by considering three specific distances evaluating discrepancy between the marginal distributions and the serial dependence patterns of both processes. Proper estimates of these dissimilarities are an essential element of the constructed tests, which are based on the bootstrap. Specifically, a parametric bootstrap method assuming the true generating models and extensions of the moving blocks bootstrap and the stationary bootstrap are considered. The approaches are assessed in a broad simulation study including several types of categorical models with different degrees of complexity. Advantages and disadvantages of each one of the methods are properly discussed according to their behavior under the null and the alternative hypothesis. The impact that some important input parameters have on the results of the tests is also analyzed. An application involving biological sequences highlights the usefulness of the proposed techniques.
Quantile-based fuzzy C-means clustering of multivariate time series: Robust techniques
Sep 22, 2021

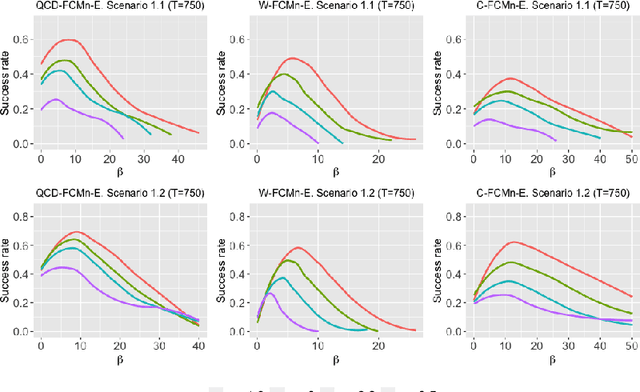

Three robust methods for clustering multivariate time series from the point of view of generating processes are proposed. The procedures are robust versions of a fuzzy C-means model based on: (i) estimates of the quantile cross-spectral density and (ii) the classical principal component analysis. Robustness to the presence of outliers is achieved by using the so-called metric, noise and trimmed approaches. The metric approach incorporates in the objective function a distance measure aimed at neutralizing the effect of the outliers, the noise approach builds an artificial cluster expected to contain the outlying series and the trimmed approach eliminates the most atypical series in the dataset. All the proposed techniques inherit the nice properties of the quantile cross-spectral density, as being able to uncover general types of dependence. Results from a broad simulation study including multivariate linear, nonlinear and GARCH processes indicate that the algorithms are substantially effective in coping with the presence of outlying series (i.e., series exhibiting a dependence structure different from that of the majority), clearly poutperforming alternative procedures. The usefulness of the suggested methods is highlighted by means of two specific applications regarding financial and environmental series.