 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convolutional Neural Network Based Approach to Recognize Bangla Spoken Digits from Speech Signal
Nov 12, 2021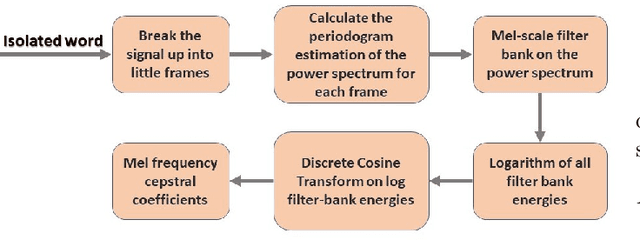

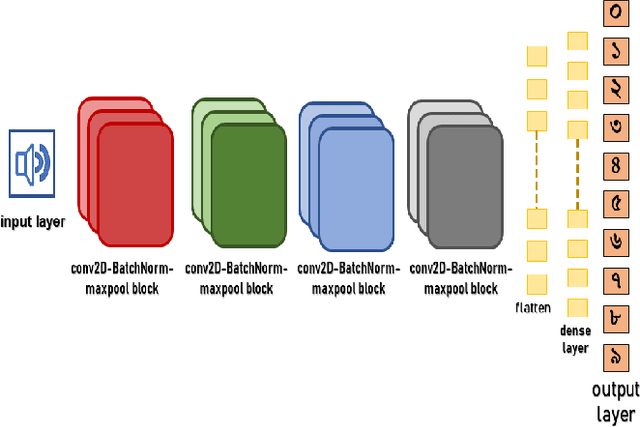
Speech recognition is a technique that converts human speech signals into text or words or in any form that can be easily understood by computers or other machines. There have been a few studies on Bangla digit recognition systems, the majority of which used small datasets with few variations in genders, ages, dialects, and other variables. Audio recordings of Bangladeshi people of various genders, ages, and dialects were used to create a large speech dataset of spoken '0-9' Bangla digits in this study. Here, 400 noisy and noise-free samples per digit have been recorded for creating the dataset. Mel Frequency Cepstrum Coefficients (MFCCs) have been utilized for extracting meaningful features from the raw speech data. Then, to detect Bangla numeral digits, Convolutional Neural Networks (CNNs) were utilized. The suggested technique recognizes '0-9' Bangla spoken digits with 97.1% accuracy throughout the whole dataset. The efficiency of the model was also assessed using 10-fold crossvalidation, which yielded a 96.7% accuracy.