 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiabetic Retinopathy Classification from Retinal Images using Machine Learning Approaches
Dec 03, 2024Diabetic Retinopathy is one of the most familiar diseases and is a diabetes complication that affects eyes. Initially, diabetic retinopathy may cause no symptoms or only mild vision problems. Eventually, it can cause blindness. So early detection of symptoms could help to avoid blindness. In this paper, we present some experiments on some features of diabetic retinopathy, like properties of exudates, properties of blood vessels and properties of microaneurysm. Using the features, we can classify healthy, mild non-proliferative, moderate non-proliferative, severe non-proliferative and proliferative stages of DR. Support Vector Machine, Random Forest and Naive Bayes classifiers are used to classify the stages. Finally, Random Forest is found to be the best for higher accuracy, sensitivity and specificity of 76.5%, 77.2% and 93.3% respectively.
A Convolutional Neural Network Based Approach to Recognize Bangla Spoken Digits from Speech Signal
Nov 12, 2021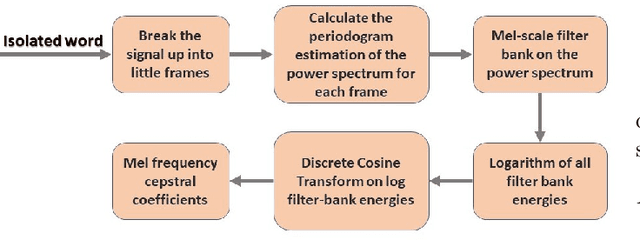

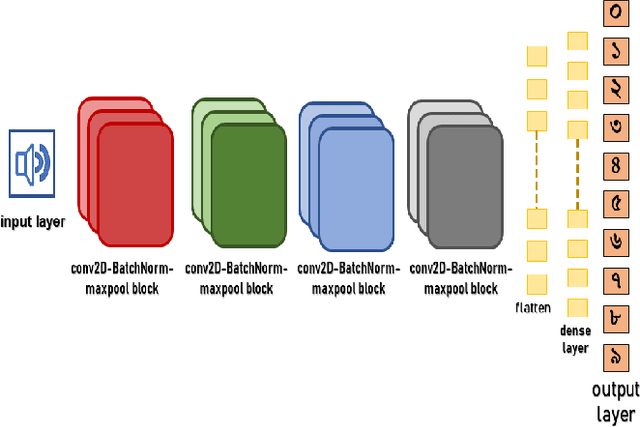
Speech recognition is a technique that converts human speech signals into text or words or in any form that can be easily understood by computers or other machines. There have been a few studies on Bangla digit recognition systems, the majority of which used small datasets with few variations in genders, ages, dialects, and other variables. Audio recordings of Bangladeshi people of various genders, ages, and dialects were used to create a large speech dataset of spoken '0-9' Bangla digits in this study. Here, 400 noisy and noise-free samples per digit have been recorded for creating the dataset. Mel Frequency Cepstrum Coefficients (MFCCs) have been utilized for extracting meaningful features from the raw speech data. Then, to detect Bangla numeral digits, Convolutional Neural Networks (CNNs) were utilized. The suggested technique recognizes '0-9' Bangla spoken digits with 97.1% accuracy throughout the whole dataset. The efficiency of the model was also assessed using 10-fold crossvalidation, which yielded a 96.7% accuracy.
Recognizing Bangla Grammar using Predictive Parser
Jan 10, 2012
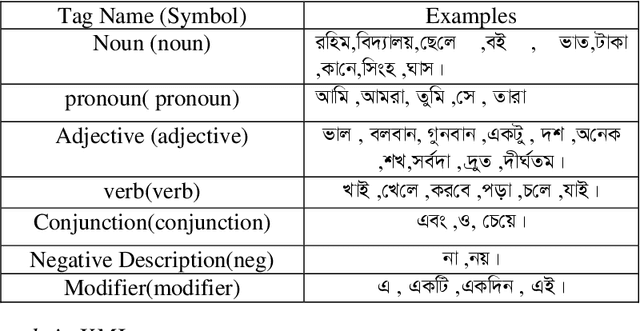
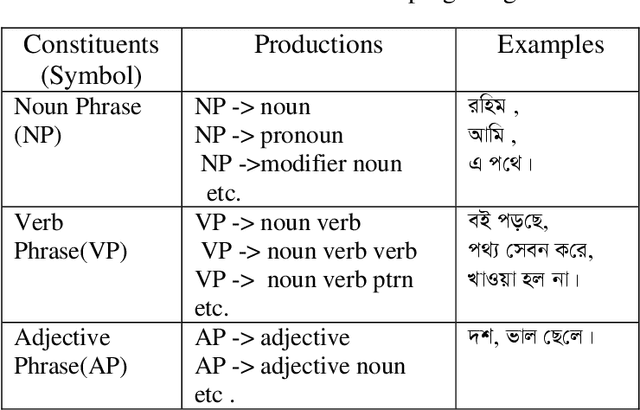

We describe a Context Free Grammar (CFG) for Bangla language and hence we propose a Bangla parser based on the grammar. Our approach is very much general to apply in Bangla Sentences and the method is well accepted for parsing a language of a grammar. The proposed parser is a predictive parser and we construct the parse table for recognizing Bangla grammar. Using the parse table we recognize syntactical mistakes of Bangla sentences when there is no entry for a terminal in the parse table. If a natural language can be successfully parsed then grammar checking from this language becomes possible. The proposed scheme is based on Top down parsing method and we have avoided the left recursion of the CFG using the idea of left factoring.