 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving Beyond Next-Token Prediction: Transformers are Context-Sensitive Language Generators
Apr 15, 2025

Large Language Models (LLMs), powered by Transformers, have demonstrated human-like intelligence capabilities, yet their underlying mechanisms remain poorly understood. This paper presents a novel framework for interpreting LLMs as probabilistic left context-sensitive languages (CSLs) generators. We hypothesize that Transformers can be effectively decomposed into three fundamental components: context windows, attention mechanisms, and autoregressive generation frameworks. This decomposition allows for the development of more flexible and interpretable computational models, moving beyond the traditional view of attention and autoregression as inseparable processes. We argue that next-token predictions can be understood as probabilistic, dynamic approximations of left CSL production rules, providing an intuitive explanation for how simple token predictions can yield human-like intelligence outputs. Given that all CSLs are left context-sensitive (Penttonen, 1974), we conclude that Transformers stochastically approximate CSLs, which are widely recognized as models of human-like intelligence. This interpretation bridges the gap between Formal Language Theory and the observed generative power of Transformers, laying a foundation for future advancements in generative AI theory and applications. Our novel perspective on Transformer architectures will foster a deeper understanding of LLMs and their future potentials.
Incremental Deep Learning for Robust Object Detection in Unknown Cluttered Environments
Oct 13, 2018
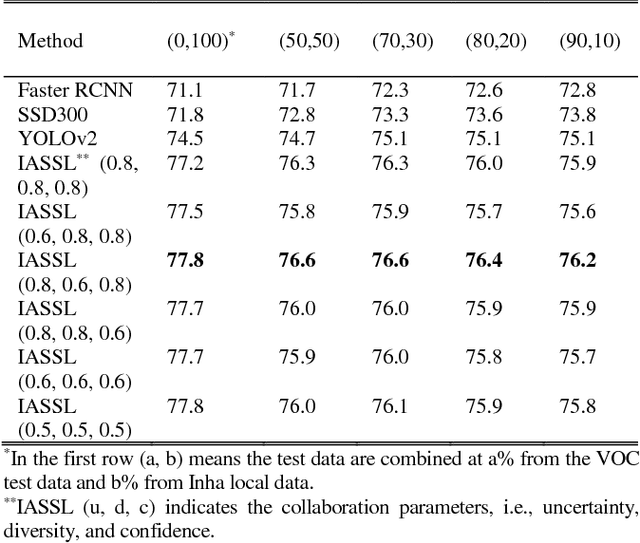

Object detection in streaming images is a major step in different detection-based applications, such as object tracking, action recognition, robot navigation, and visual surveillance applications. In mostcases, image quality is noisy and biased, and as a result, the data distributions are disturbed and imbalanced. Most object detection approaches, such as the faster region-based convolutional neural network (Faster RCNN), Single Shot Multibox Detector with 300x300 inputs (SSD300), and You Only Look Once version 2 (YOLOv2), rely on simple sampling without considering distortions and noise under real-world changing environments, despite poor object labeling. In this paper, we propose an Incremental active semi-supervised learning (IASSL) technology for unseen object detection. It combines batch-based active learning (AL) and bin-based semi-supervised learning (SSL) to leverage the strong points of AL's exploration and SSL's exploitation capabilities. A collaborative sampling method is also adopted to measure the uncertainty and diversity of AL and the confidence in SSL. Batch-based AL allows us to select more informative, confident, and representative samples with low cost. Bin-based SSL divides streaming image samples into several bins, and each bin repeatedly transfers the discriminative knowledge of convolutional neural network (CNN) deep learning to the next bin until the performance criterion is reached. IASSL can overcome noisy and biased labels in unknown, cluttered data distributions. We obtain superior performance, compared to state-of-the-art technologies such as Faster RCNN, SSD300, and YOLOv2.
Multi-Class Multi-Object Tracking using Changing Point Detection
Aug 30, 2016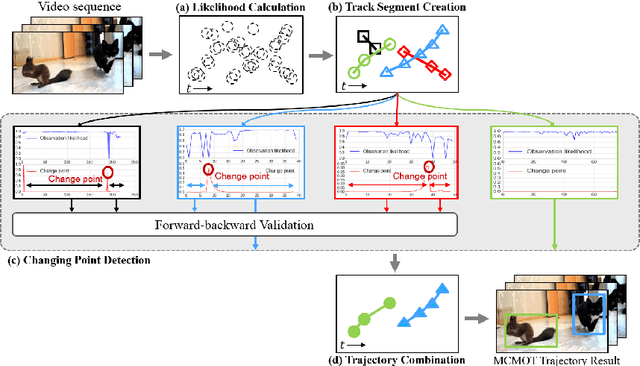
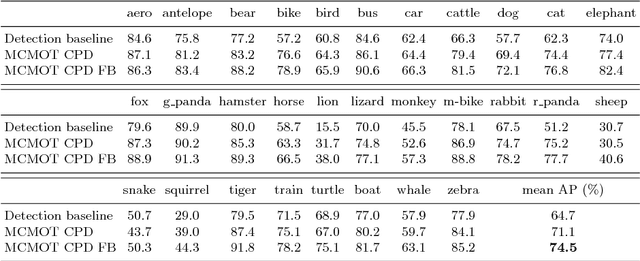
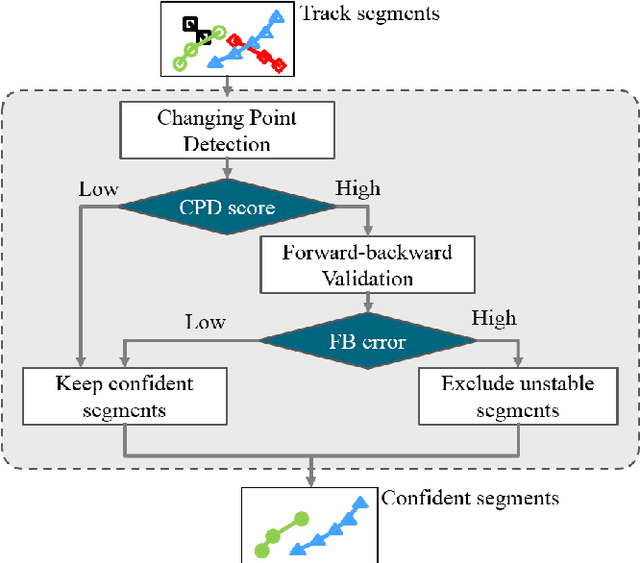
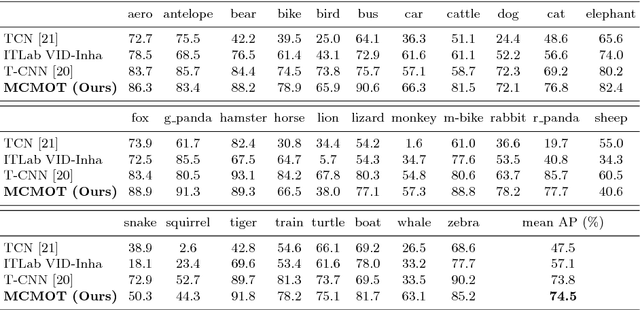
This paper presents a robust multi-class multi-object tracking (MCMOT) formulated by a Bayesian filtering framework. Multi-object tracking for unlimited object classes is conducted by combining detection responses and changing point detection (CPD) algorithm. The CPD model is used to observe abrupt or abnormal changes due to a drift and an occlusion based spatiotemporal characteristics of track states. The ensemble of convolutional neural network (CNN) based object detector and Lucas-Kanede Tracker (KLT) based motion detector is employed to compute the likelihoods of foreground regions as the detection responses of different object classes. Extensive experiments are performed using lately introduced challenging benchmark videos; ImageNet VID and MOT benchmark dataset. The comparison to state-of-the-art video tracking techniques shows very encouraging results.