 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedicine on the Edge: Comparative Performance Analysis of On-Device LLMs for Clinical Reasoning
Feb 13, 2025The deployment of Large Language Models (LLM) on mobile devices offers significant potential for medical applications, enhancing privacy, security, and cost-efficiency by eliminating reliance on cloud-based services and keeping sensitive health data local. However, the performance and accuracy of on-device LLMs in real-world medical contexts remain underexplored. In this study, we benchmark publicly available on-device LLMs using the AMEGA dataset, evaluating accuracy, computational efficiency, and thermal limitation across various mobile devices. Our results indicate that compact general-purpose models like Phi-3 Mini achieve a strong balance between speed and accuracy, while medically fine-tuned models such as Med42 and Aloe attain the highest accuracy. Notably, deploying LLMs on older devices remains feasible, with memory constraints posing a greater challenge than raw processing power. Our study underscores the potential of on-device LLMs for healthcare while emphasizing the need for more efficient inference and models tailored to real-world clinical reasoning.
Dynamic Fog Computing for Enhanced LLM Execution in Medical Applications
Aug 08, 2024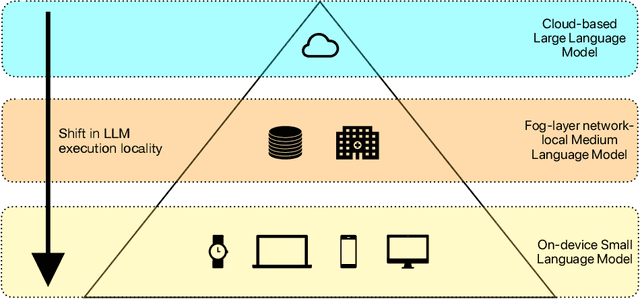

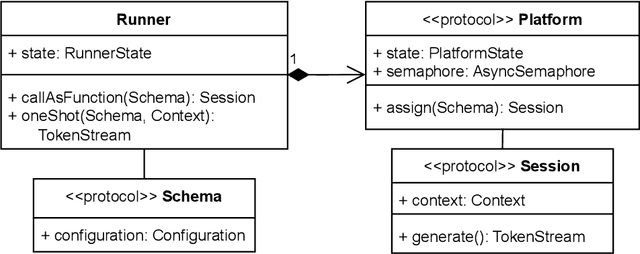
The ability of large language models (LLMs) to transform, interpret, and comprehend vast quantities of heterogeneous data presents a significant opportunity to enhance data-driven care delivery. However, the sensitive nature of protected health information (PHI) raises valid concerns about data privacy and trust in remote LLM platforms. In addition, the cost associated with cloud-based artificial intelligence (AI) services continues to impede widespread adoption. To address these challenges, we propose a shift in the LLM execution environment from opaque, centralized cloud providers to a decentralized and dynamic fog computing architecture. By executing open-weight LLMs in more trusted environments, such as the user's edge device or a fog layer within a local network, we aim to mitigate the privacy, trust, and financial challenges associated with cloud-based LLMs. We further present SpeziLLM, an open-source framework designed to facilitate rapid and seamless leveraging of different LLM execution layers and lowering barriers to LLM integration in digital health applications. We demonstrate SpeziLLM's broad applicability across six digital health applications, showcasing its versatility in various healthcare settings.
LLM on FHIR -- Demystifying Health Records
Jan 25, 2024Objective: To enhance health literacy and accessibility of health information for a diverse patient population by developing a patient-centered artificial intelligence (AI) solution using large language models (LLMs) and Fast Healthcare Interoperability Resources (FHIR) application programming interfaces (APIs). Materials and Methods: The research involved developing LLM on FHIR, an open-source mobile application allowing users to interact with their health records using LLMs. The app is built on Stanford's Spezi ecosystem and uses OpenAI's GPT-4. A pilot study was conducted with the SyntheticMass patient dataset and evaluated by medical experts to assess the app's effectiveness in increasing health literacy. The evaluation focused on the accuracy, relevance, and understandability of the LLM's responses to common patient questions. Results: LLM on FHIR demonstrated varying but generally high degrees of accuracy and relevance in providing understandable health information to patients. The app effectively translated medical data into patient-friendly language and was able to adapt its responses to different patient profiles. However, challenges included variability in LLM responses and the need for precise filtering of health data. Discussion and Conclusion: LLMs offer significant potential in improving health literacy and making health records more accessible. LLM on FHIR, as a pioneering application in this field, demonstrates the feasibility and challenges of integrating LLMs into patient care. While promising, the implementation and pilot also highlight risks such as inconsistent responses and the importance of replicable output. Future directions include better resource identification mechanisms and executing LLMs on-device to enhance privacy and reduce costs.