 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Different Simulated Spectral Data and Machine Learning to Estimate the Chlorophyll $a$ Concentration of Several Inland Waters
May 29, 2019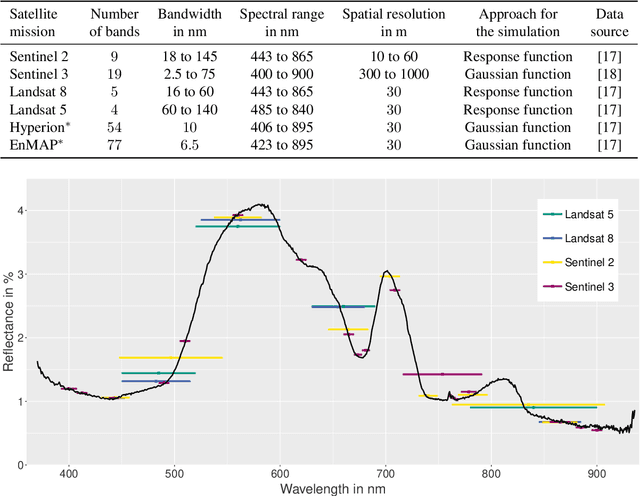

Water quality is of great importance for humans and for the environment and has to be monitored continuously. It is determinable through proxies such as the chlorophyll $a$ concentration, which can be monitored by remote sensing techniques. This study focuses on the trade-off between the spatial and the spectral resolution of six simulated satellite-based data sets when estimating the chlorophyll $a$ concentration with supervised machine learning models. The initial dataset for the spectral simulation of the satellite missions contains spectrometer data and measured chlorophyll $a$ concentration of 13 different inland waters. Focusing on the regression performance, it appears that the machine learning models achieve almost as good results with the simulated Sentinel data as with the simulated hyperspectral data. Regarding the applicability, the Sentinel 2 mission is the best choice for small inland waters due to its high spatial and temporal resolution in combination with a suitable spectral resolution.
Estimating Chlorophyll a Concentrations of Several Inland Waters with Hyperspectral Data and Machine Learning Models
Apr 03, 2019



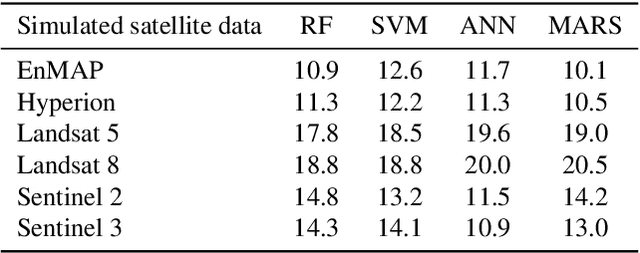
Water is a key component of life, the natural environment and human health. For monitoring the conditions of a water body, the chlorophyll a concentration can serve as a proxy for nutrients and oxygen supply. In situ measurements of water quality parameters are often time-consuming, expensive and limited in areal validity. Therefore, we apply remote sensing techniques. During field campaigns, we collected hyperspectral data with a spectrometer and in situ measured chlorophyll a concentrations of 13 inland water bodies with different spectral characteristics. One objective of this study is to estimate chlorophyll a concentrations of these inland waters by applying three machine learning regression models: Random Forest, Support Vector Machine and an Artificial Neural Network. Additionally, we simulate four different hyperspectral resolutions of the spectrometer data to investigate the effects on the estimation performance. Furthermore, the application of first order derivatives of the spectra is evaluated in turn to the regression performance. This study reveals the potential of combining machine learning approaches and remote sensing data for inland waters. Each machine learning model achieves an R2-score between 80 % to 90 % for the regression on chlorophyll a concentrations. The random forest model benefits clearly from the applied derivatives of the spectra. In further studies, we will focus on the application of machine learning models on spectral satellite data to enhance the area-wide estimation of chlorophyll a concentration for inland waters.
Machine learning regression on hyperspectral data to estimate multiple water parameters
Aug 07, 2018


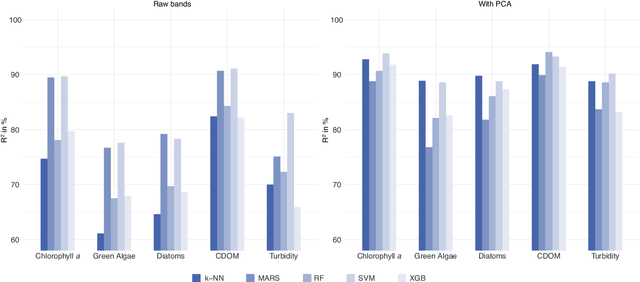
In this paper, we present a regression framework involving several machine learning models to estimate water parameters based on hyperspectral data. Measurements from a multi-sensor field campaign, conducted on the River Elbe, Germany, represent the benchmark dataset. It contains hyperspectral data and the five water parameters chlorophyll a, green algae, diatoms, CDOM and turbidity. We apply a PCA for the high-dimensional data as a possible preprocessing step. Then, we evaluate the performance of the regression framework with and without this preprocessing step. The regression results of the framework clearly reveal the potential of estimating water parameters based on hyperspectral data with machine learning. The proposed framework provides the basis for further investigations, such as adapting the framework to estimate water parameters of different inland waters.
Developing a machine learning framework for estimating soil moisture with VNIR hyperspectral data
Jul 12, 2018
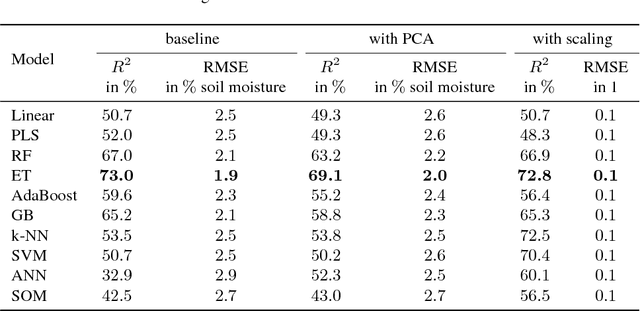
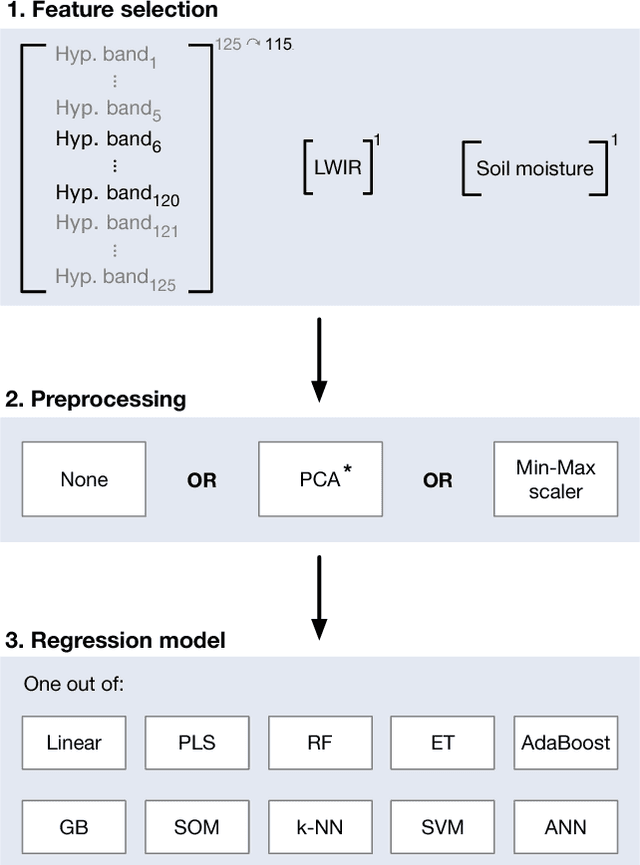
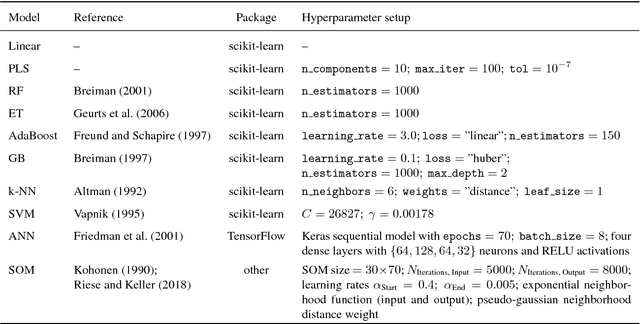
In this paper, we investigate the potential of estimating the soil-moisture content based on VNIR hyperspectral data combined with LWIR data. Measurements from a multi-sensor field campaign represent the benchmark dataset which contains measured hyperspectral, LWIR, and soil-moisture data conducted on grassland site. We introduce a regression framework with three steps consisting of feature selection, preprocessing, and well-chosen regression models. The latter are mainly supervised machine learning models. An exception are the self-organizing maps which combine unsupervised and supervised learning. We analyze the impact of the distinct preprocessing methods on the regression results. Of all regression models, the extremely randomized trees model without preprocessing provides the best estimation performance. Our results reveal the potential of the respective regression framework combined with the VNIR hyperspectral data to estimate soil moisture measured under real-world conditions. In conclusion, the results of this paper provide a basis for further improvements in different research directions.
* Accepted at ISPRS TC I Midterm Symposium Karlsruhe (October 2018)