 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoping Review of Active Learning Strategies and their Evaluation Environments for Entity Recognition Tasks
Jul 04, 2024We conducted a scoping review for active learning in the domain of natural language processing (NLP), which we summarize in accordance with the PRISMA-ScR guidelines as follows: Objective: Identify active learning strategies that were proposed for entity recognition and their evaluation environments (datasets, metrics, hardware, execution time). Design: We used Scopus and ACM as our search engines. We compared the results with two literature surveys to assess the search quality. We included peer-reviewed English publications introducing or comparing active learning strategies for entity recognition. Results: We analyzed 62 relevant papers and identified 106 active learning strategies. We grouped them into three categories: exploitation-based (60x), exploration-based (14x), and hybrid strategies (32x). We found that all studies used the F1-score as an evaluation metric. Information about hardware (6x) and execution time (13x) was only occasionally included. The 62 papers used 57 different datasets to evaluate their respective strategies. Most datasets contained newspaper articles or biomedical/medical data. Our analysis revealed that 26 out of 57 datasets are publicly accessible. Conclusion: Numerous active learning strategies have been identified, along with significant open questions that still need to be addressed. Researchers and practitioners face difficulties when making data-driven decisions about which active learning strategy to adopt. Conducting comprehensive empirical comparisons using the evaluation environment proposed in this study could help establish best practices in the domain.
Explaining Relation Classification Models with Semantic Extents
Aug 04, 2023In recent years, the development of large pretrained language models, such as BERT and GPT, significantly improved information extraction systems on various tasks, including relation classification. State-of-the-art systems are highly accurate on scientific benchmarks. A lack of explainability is currently a complicating factor in many real-world applications. Comprehensible systems are necessary to prevent biased, counterintuitive, or harmful decisions. We introduce semantic extents, a concept to analyze decision patterns for the relation classification task. Semantic extents are the most influential parts of texts concerning classification decisions. Our definition allows similar procedures to determine semantic extents for humans and models. We provide an annotation tool and a software framework to determine semantic extents for humans and models conveniently and reproducibly. Comparing both reveals that models tend to learn shortcut patterns from data. These patterns are hard to detect with current interpretability methods, such as input reductions. Our approach can help detect and eliminate spurious decision patterns during model development. Semantic extents can increase the reliability and security of natural language processing systems. Semantic extents are an essential step in enabling applications in critical areas like healthcare or finance. Moreover, our work opens new research directions for developing methods to explain deep learning models.
ALE: A Simulation-Based Active Learning Evaluation Framework for the Parameter-Driven Comparison of Query Strategies for NLP
Aug 01, 2023Supervised machine learning and deep learning require a large amount of labeled data, which data scientists obtain in a manual, and time-consuming annotation process. To mitigate this challenge, Active Learning (AL) proposes promising data points to annotators they annotate next instead of a subsequent or random sample. This method is supposed to save annotation effort while maintaining model performance. However, practitioners face many AL strategies for different tasks and need an empirical basis to choose between them. Surveys categorize AL strategies into taxonomies without performance indications. Presentations of novel AL strategies compare the performance to a small subset of strategies. Our contribution addresses the empirical basis by introducing a reproducible active learning evaluation (ALE) framework for the comparative evaluation of AL strategies in NLP. The framework allows the implementation of AL strategies with low effort and a fair data-driven comparison through defining and tracking experiment parameters (e.g., initial dataset size, number of data points per query step, and the budget). ALE helps practitioners to make more informed decisions, and researchers can focus on developing new, effective AL strategies and deriving best practices for specific use cases. With best practices, practitioners can lower their annotation costs. We present a case study to illustrate how to use the framework.
* The Version of Record of this contribution is published in Deep Learning Theory and Applications 4th International Conference, DeLTA 2023 Proceedings, and is available online at https://doi.org/10.1007/978-3-031-39059-3_16
Multi-Attribute Relation Extraction (MARE) -- Simplifying the Application of Relation Extraction
Nov 17, 2021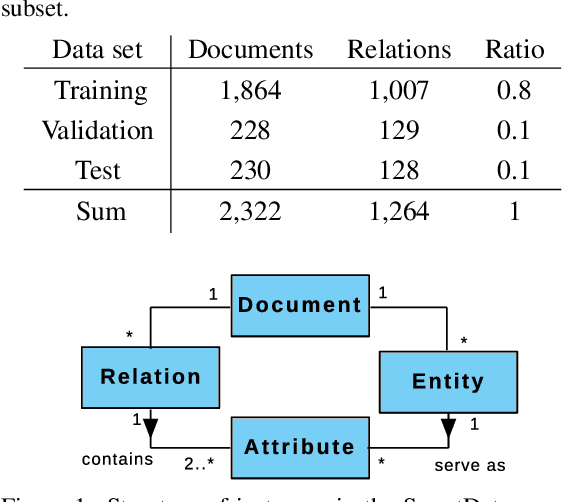
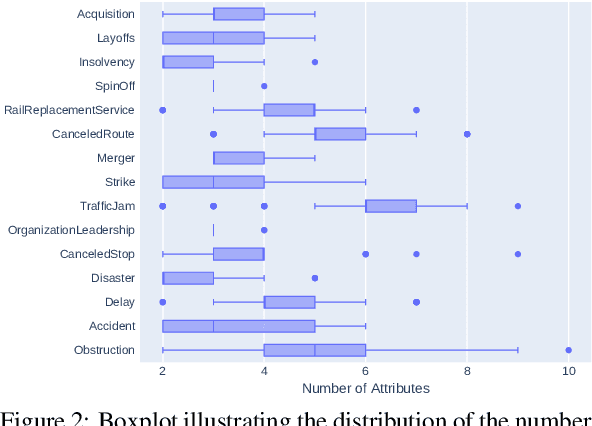

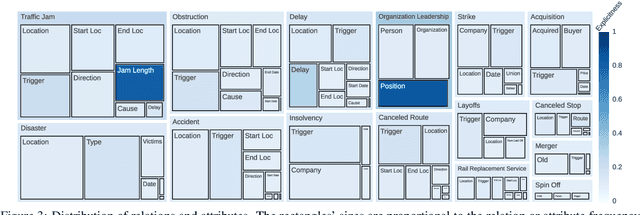
Natural language understanding's relation extraction makes innovative and encouraging novel business concepts possible and facilitates new digitilized decision-making processes. Current approaches allow the extraction of relations with a fixed number of entities as attributes. Extracting relations with an arbitrary amount of attributes requires complex systems and costly relation-trigger annotations to assist these systems. We introduce multi-attribute relation extraction (MARE) as an assumption-less problem formulation with two approaches, facilitating an explicit mapping from business use cases to the data annotations. Avoiding elaborated annotation constraints simplifies the application of relation extraction approaches. The evaluation compares our models to current state-of-the-art event extraction and binary relation extraction methods. Our approaches show improvement compared to these on the extraction of general multi-attribute relations.
* Preprint of short paper for the 2nd International Conference on Deep Learning Theory and Applications (2021)
STAMP 4 NLP -- An Agile Framework for Rapid Quality-Driven NLP Applications Development
Nov 16, 2021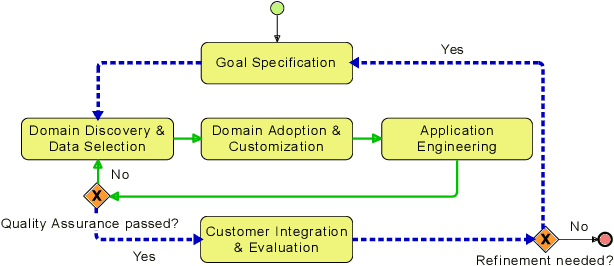
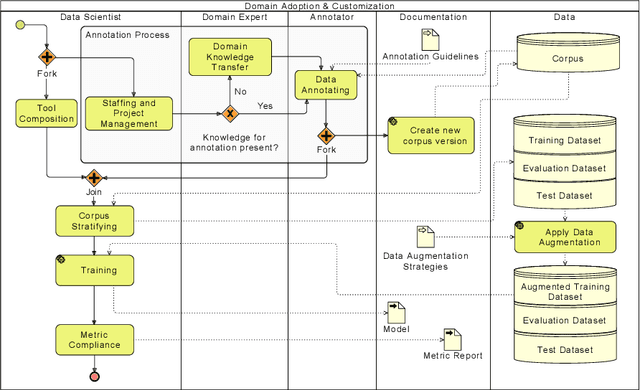

The progress in natural language processing (NLP) research over the last years, offers novel business opportunities for companies, as automated user interaction or improved data analysis. Building sophisticated NLP applications requires dealing with modern machine learning (ML) technologies, which impedes enterprises from establishing successful NLP projects. Our experience in applied NLP research projects shows that the continuous integration of research prototypes in production-like environments with quality assurance builds trust in the software and shows convenience and usefulness regarding the business goal. We introduce STAMP 4 NLP as an iterative and incremental process model for developing NLP applications. With STAMP 4 NLP, we merge software engineering principles with best practices from data science. Instantiating our process model allows efficiently creating prototypes by utilizing templates, conventions, and implementations, enabling developers and data scientists to focus on the business goals. Due to our iterative-incremental approach, businesses can deploy an enhanced version of the prototype to their software environment after every iteration, maximizing potential business value and trust early and avoiding the cost of successful yet never deployed experiments.
* Preprint of short paper for QUATIC 2021 conference