 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALE: A Simulation-Based Active Learning Evaluation Framework for the Parameter-Driven Comparison of Query Strategies for NLP
Aug 01, 2023Supervised machine learning and deep learning require a large amount of labeled data, which data scientists obtain in a manual, and time-consuming annotation process. To mitigate this challenge, Active Learning (AL) proposes promising data points to annotators they annotate next instead of a subsequent or random sample. This method is supposed to save annotation effort while maintaining model performance. However, practitioners face many AL strategies for different tasks and need an empirical basis to choose between them. Surveys categorize AL strategies into taxonomies without performance indications. Presentations of novel AL strategies compare the performance to a small subset of strategies. Our contribution addresses the empirical basis by introducing a reproducible active learning evaluation (ALE) framework for the comparative evaluation of AL strategies in NLP. The framework allows the implementation of AL strategies with low effort and a fair data-driven comparison through defining and tracking experiment parameters (e.g., initial dataset size, number of data points per query step, and the budget). ALE helps practitioners to make more informed decisions, and researchers can focus on developing new, effective AL strategies and deriving best practices for specific use cases. With best practices, practitioners can lower their annotation costs. We present a case study to illustrate how to use the framework.
* The Version of Record of this contribution is published in Deep Learning Theory and Applications 4th International Conference, DeLTA 2023 Proceedings, and is available online at https://doi.org/10.1007/978-3-031-39059-3_16
STAMP 4 NLP -- An Agile Framework for Rapid Quality-Driven NLP Applications Development
Nov 16, 2021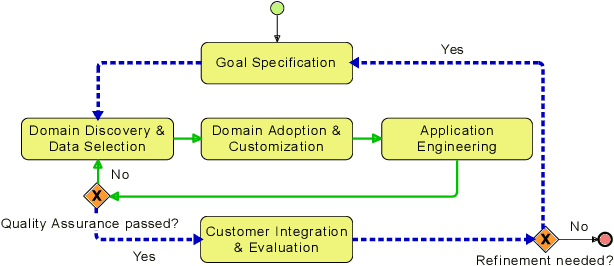
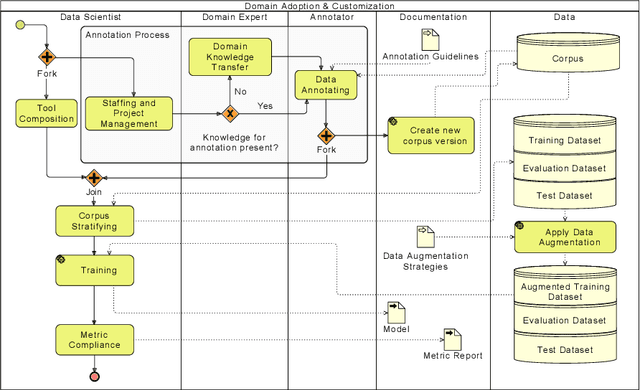

The progress in natural language processing (NLP) research over the last years, offers novel business opportunities for companies, as automated user interaction or improved data analysis. Building sophisticated NLP applications requires dealing with modern machine learning (ML) technologies, which impedes enterprises from establishing successful NLP projects. Our experience in applied NLP research projects shows that the continuous integration of research prototypes in production-like environments with quality assurance builds trust in the software and shows convenience and usefulness regarding the business goal. We introduce STAMP 4 NLP as an iterative and incremental process model for developing NLP applications. With STAMP 4 NLP, we merge software engineering principles with best practices from data science. Instantiating our process model allows efficiently creating prototypes by utilizing templates, conventions, and implementations, enabling developers and data scientists to focus on the business goals. Due to our iterative-incremental approach, businesses can deploy an enhanced version of the prototype to their software environment after every iteration, maximizing potential business value and trust early and avoiding the cost of successful yet never deployed experiments.
* Preprint of short paper for QUATIC 2021 conference