 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimLTD: Simple Supervised and Semi-Supervised Long-Tailed Object Detection
Dec 28, 2024



Recent years have witnessed tremendous advances on modern visual recognition systems. Despite such progress, many vision models still struggle with the open problem of learning from few exemplars. This paper focuses on the task of object detection in the setting where object classes follow a natural long-tailed distribution. Existing approaches to long-tailed detection resort to external ImageNet labels to augment the low-shot training instances. However, such dependency on a large labeled database is impractical and has limited utility in realistic scenarios. We propose a more versatile approach to leverage optional unlabeled images, which are easy to collect without the burden of human annotations. Our SimLTD framework is straightforward and intuitive, and consists of three simple steps: (1) pre-training on abundant head classes; (2) transfer learning on scarce tail classes; and (3) fine-tuning on a sampled set of both head and tail classes. Our approach can be viewed as an improved head-to-tail model transfer paradigm without the added complexities of meta-learning or knowledge distillation, as was required in past research. By harnessing supplementary unlabeled images, without extra image labels, SimLTD establishes new record results on the challenging LVIS v1 benchmark across both supervised and semi-supervised settings.
Boosting Semi-Supervised Few-Shot Object Detection with SoftER Teacher
Mar 10, 2023

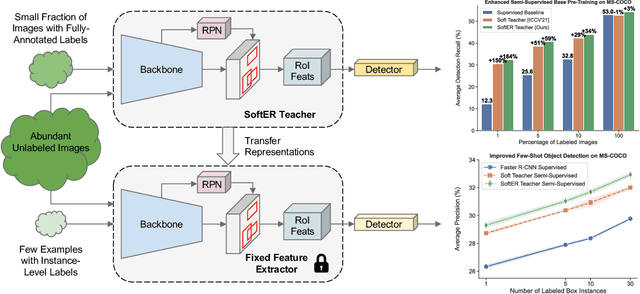

Few-shot object detection is an emerging problem aimed at detecting novel concepts from few exemplars. Existing approaches to few-shot detection assume abundant base labels to adapt to novel objects. This paper explores the task of semi-supervised few-shot detection by considering a realistic scenario which lacks abundant labels for both base and novel objects. Motivated by this unique problem, we introduce SoftER Teacher, a robust detector combining the advantages of pseudo-labeling with representation learning on region proposals. SoftER Teacher harnesses unlabeled data to jointly optimize for semi-supervised few-shot detection without explicitly relying on abundant base labels. Extensive experiments show that SoftER Teacher matches the novel class performance of a strong supervised detector using only 10% of base labels. Our work also sheds insight into a previously unknown relationship between semi-supervised and few-shot detection to suggest that a stronger semi-supervised detector leads to a more label-efficient few-shot detector. Code and models are available at https://github.com/lexisnexis-risk-open-source/ledetection
SSLayout360: Semi-Supervised Indoor Layout Estimation from 360-Degree Panorama
Mar 29, 2021
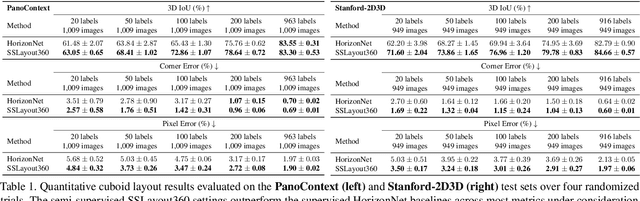
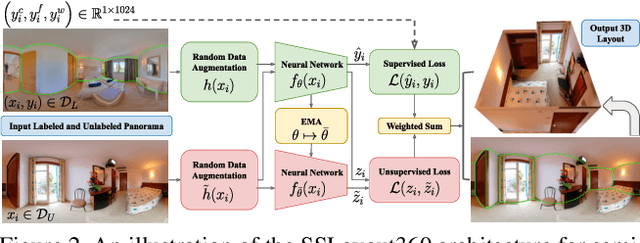
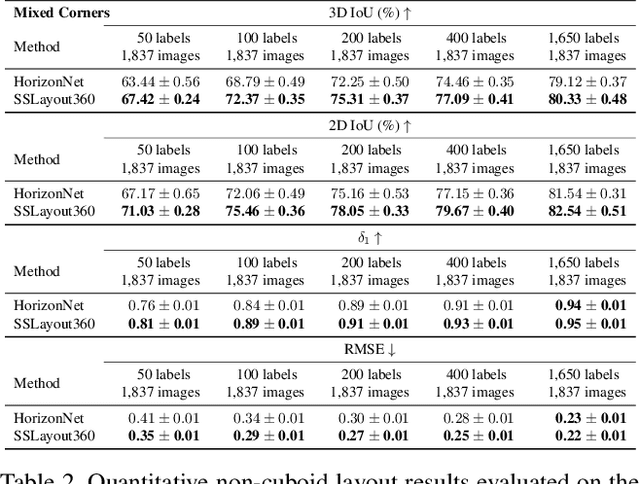
Recent years have seen flourishing research on both semi-supervised learning and 3D room layout reconstruction. In this work, we explore the intersection of these two fields to advance the research objective of enabling more accurate 3D indoor scene modeling with less labeled data. We propose the first approach to learn representations of room corners and boundaries by using a combination of labeled and unlabeled data for improved layout estimation in a 360-degree panoramic scene. Through extensive comparative experiments, we demonstrate that our approach can advance layout estimation of complex indoor scenes using as few as 20 labeled examples. When coupled with a layout predictor pre-trained on synthetic data, our semi-supervised method matches the fully supervised counterpart using only 12% of the labels. Our work takes an important first step towards robust semi-supervised layout estimation that can enable many applications in 3D perception with limited labeled data.
Semi-Supervised Learning with Self-Supervised Networks
Jun 25, 2019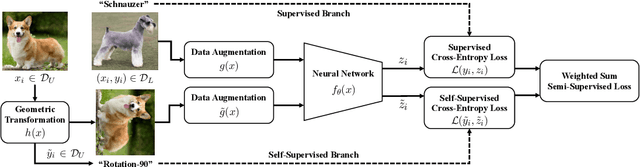
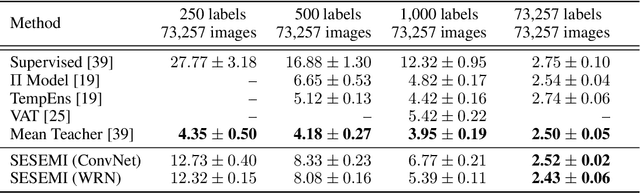
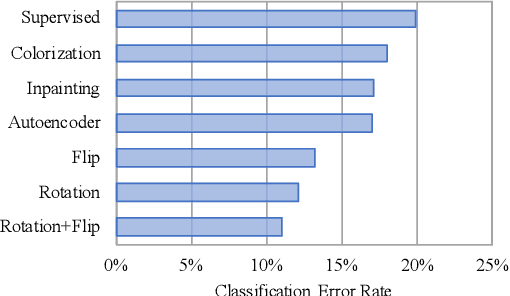
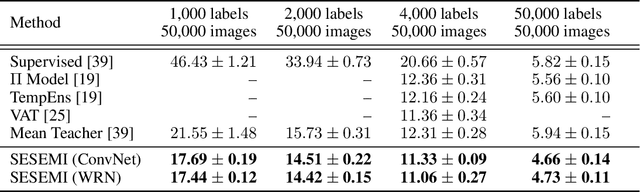
Recent advances in semi-supervised learning have shown tremendous potential in overcoming a major barrier to the success of modern machine learning algorithms: access to vast amounts of human-labeled training data. Algorithms based on self-ensemble learning and virtual adversarial training can harness the abundance of unlabeled data to produce impressive state-of-the-art results on a number of semi-supervised benchmarks, approaching the performance of strong supervised baselines using only a fraction of the available labeled data. However, these methods often require careful tuning of many hyper-parameters and are usually not easy to implement in practice. In this work, we present a conceptually simple yet effective semi-supervised algorithm based on self-supervised learning to combine semantic feature representations from unlabeled data. Our models are efficiently trained end-to-end for the joint, multi-task learning of labeled and unlabeled data in a single stage. Striving for simplicity and practicality, our approach requires no additional hyper-parameters to tune for optimal performance beyond the standard set for training convolutional neural networks. We conduct a comprehensive empirical evaluation of our models for semi-supervised image classification on SVHN, CIFAR-10 and CIFAR-100, and demonstrate results competitive with, and in some cases exceeding, prior state of the art. Reference code and data are available at https://github.com/vuptran/sesemi
Multi-Task Graph Autoencoders
Nov 07, 2018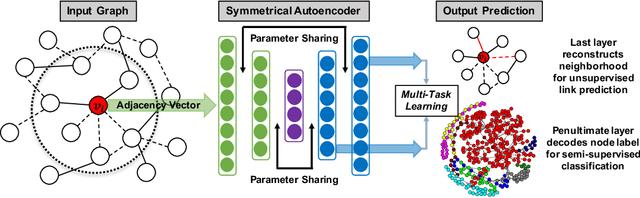

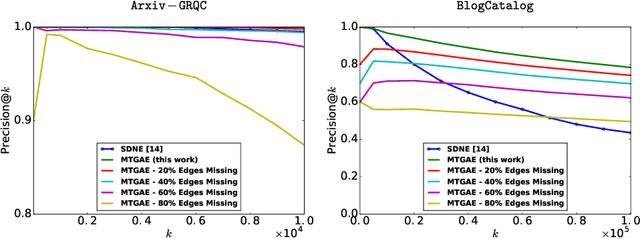

We examine two fundamental tasks associated with graph representation learning: link prediction and node classification. We present a new autoencoder architecture capable of learning a joint representation of local graph structure and available node features for the simultaneous multi-task learning of unsupervised link prediction and semi-supervised node classification. Our simple, yet effective and versatile model is efficiently trained end-to-end in a single stage, whereas previous related deep graph embedding methods require multiple training steps that are difficult to optimize. We provide an empirical evaluation of our model on five benchmark relational, graph-structured datasets and demonstrate significant improvement over three strong baselines for graph representation learning. Reference code and data are available at https://github.com/vuptran/graph-representation-learning
Learning to Make Predictions on Graphs with Autoencoders
Jul 29, 2018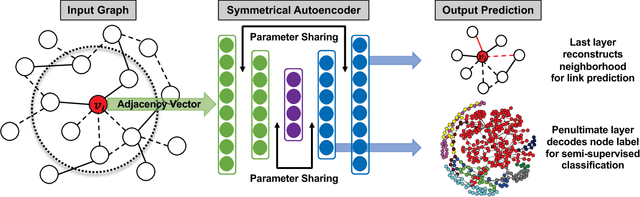
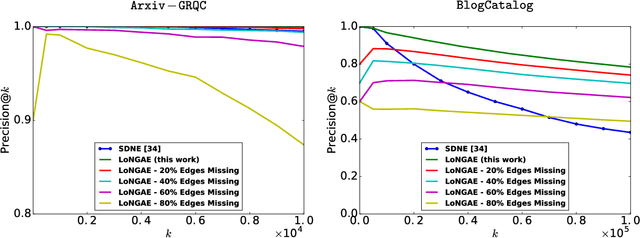
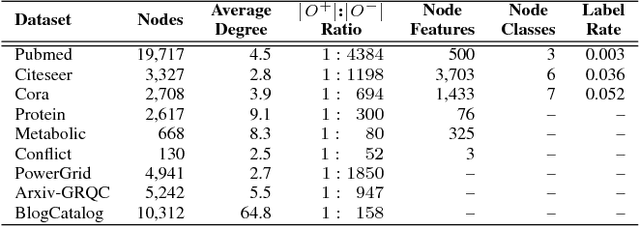

We examine two fundamental tasks associated with graph representation learning: link prediction and semi-supervised node classification. We present a novel autoencoder architecture capable of learning a joint representation of both local graph structure and available node features for the multi-task learning of link prediction and node classification. Our autoencoder architecture is efficiently trained end-to-end in a single learning stage to simultaneously perform link prediction and node classification, whereas previous related methods require multiple training steps that are difficult to optimize. We provide a comprehensive empirical evaluation of our models on nine benchmark graph-structured datasets and demonstrate significant improvement over related methods for graph representation learning. Reference code and data are available at https://github.com/vuptran/graph-representation-learning
A Fully Convolutional Neural Network for Cardiac Segmentation in Short-Axis MRI
Apr 27, 2017



Automated cardiac segmentation from magnetic resonance imaging datasets is an essential step in the timely diagnosis and management of cardiac pathologies. We propose to tackle the problem of automated left and right ventricle segmentation through the application of a deep fully convolutional neural network architecture. Our model is efficiently trained end-to-end in a single learning stage from whole-image inputs and ground truths to make inference at every pixel. To our knowledge, this is the first application of a fully convolutional neural network architecture for pixel-wise labeling in cardiac magnetic resonance imaging. Numerical experiments demonstrate that our model is robust to outperform previous fully automated methods across multiple evaluation measures on a range of cardiac datasets. Moreover, our model is fast and can leverage commodity compute resources such as the graphics processing unit to enable state-of-the-art cardiac segmentation at massive scales. The models and code are available at https://github.com/vuptran/cardiac-segmentation