 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighborhood Watch: Representation Learning with Local-Margin Triplet Loss and Sampling Strategy for K-Nearest-Neighbor Image Classification
Oct 28, 2019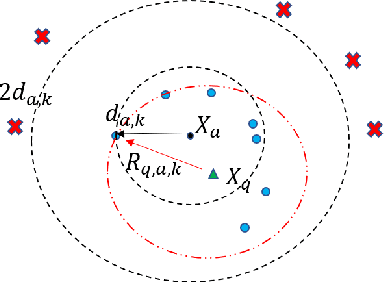
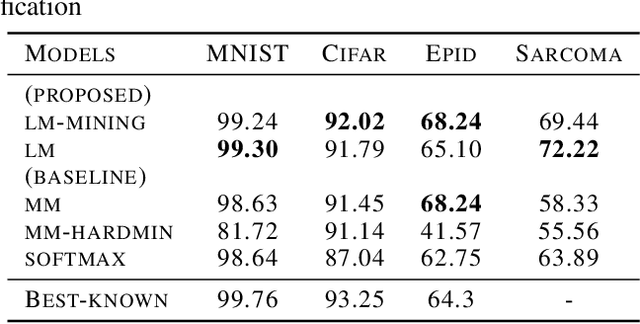

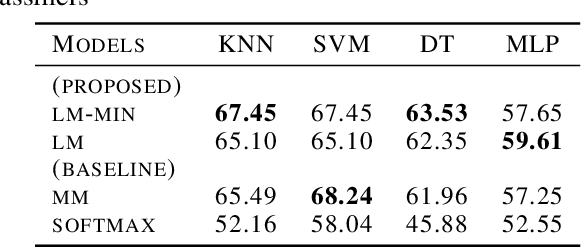
Deep representation learning using triplet network for classification suffers from a lack of theoretical foundation and difficulty in tuning both the network and classifiers for performance. To address the problem, local-margin triplet loss along with local positive and negative mining strategy is proposed with theory on how the strategy integrate nearest-neighbor hyper-parameter with triplet learning to increase subsequent classification performance. Results in experiments with 2 public datasets, MNIST and Cifar-10, and 2 small medical image datasets demonstrate that proposed strategy outperforms end-to-end softmax and typical triplet loss in settings without data augmentation while maintaining utility of transferable feature for related tasks. The method serves as a good performance baseline where end-to-end methods encounter difficulties such as small sample data with limited allowable data augmentation.