 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Deep Neural Networks "Robust"?
Aug 25, 2020Separating outliers from inliers is the definition of robustness in computer vision. This essay delineates how deep neural networks are different than typical robust estimators. Deep neural networks not robust by this traditional definition.
Scale Adaptive Clustering of Multiple Structures
Sep 26, 2017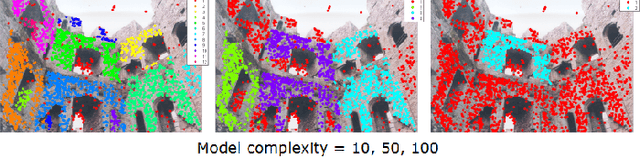

We propose the segmentation of noisy datasets into Multiple Inlier Structures with a new Robust Estimator (MISRE). The scale of each individual structure is estimated adaptively from the input data and refined by mean shift, without tuning any parameter in the process, or manually specifying thresholds for different estimation problems. Once all the data points were classified into separate structures, these structures are sorted by their densities with the strongest inlier structures coming out first. Several 2D and 3D synthetic and real examples are presented to illustrate the efficiency, robustness and the limitations of the MISRE algorithm.
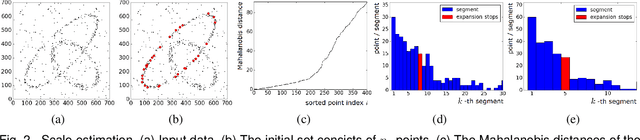
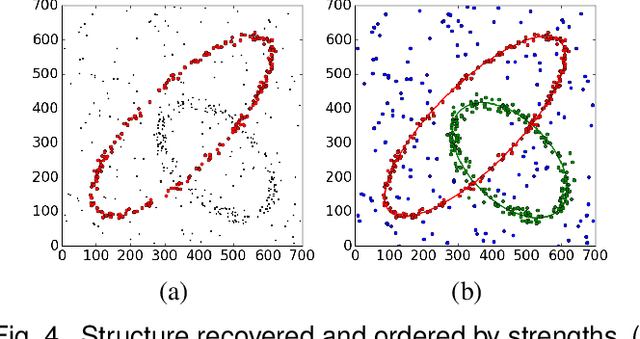
Robust Estimation of Multiple Inlier Structures
Apr 19, 2017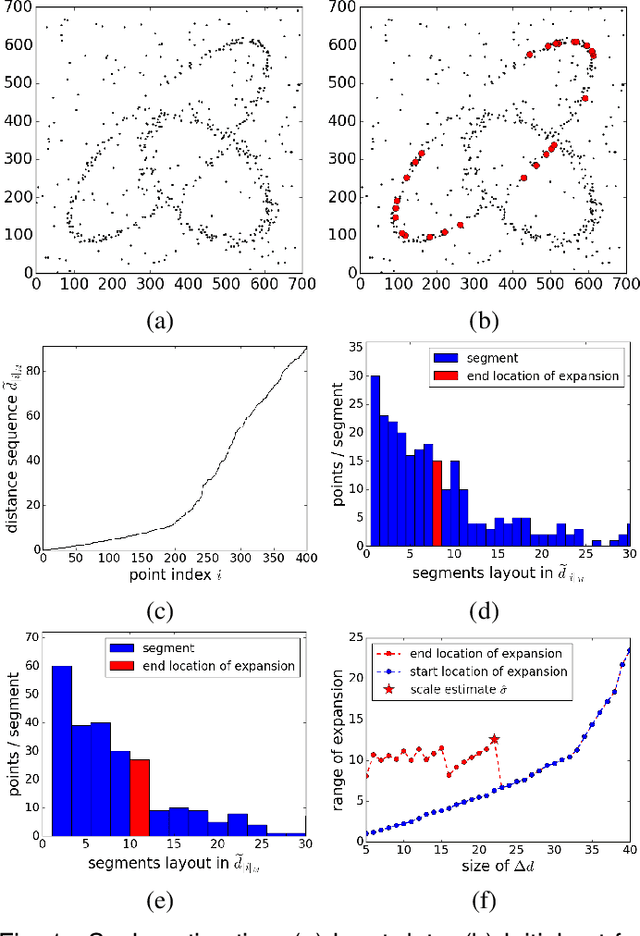

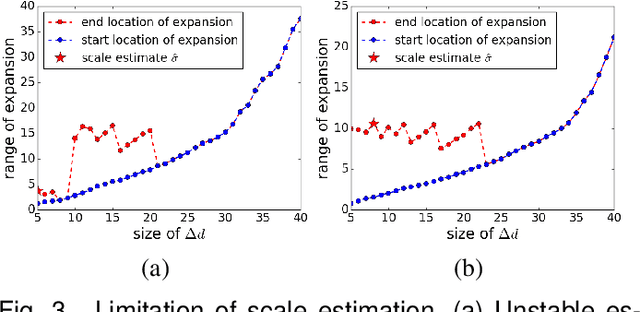
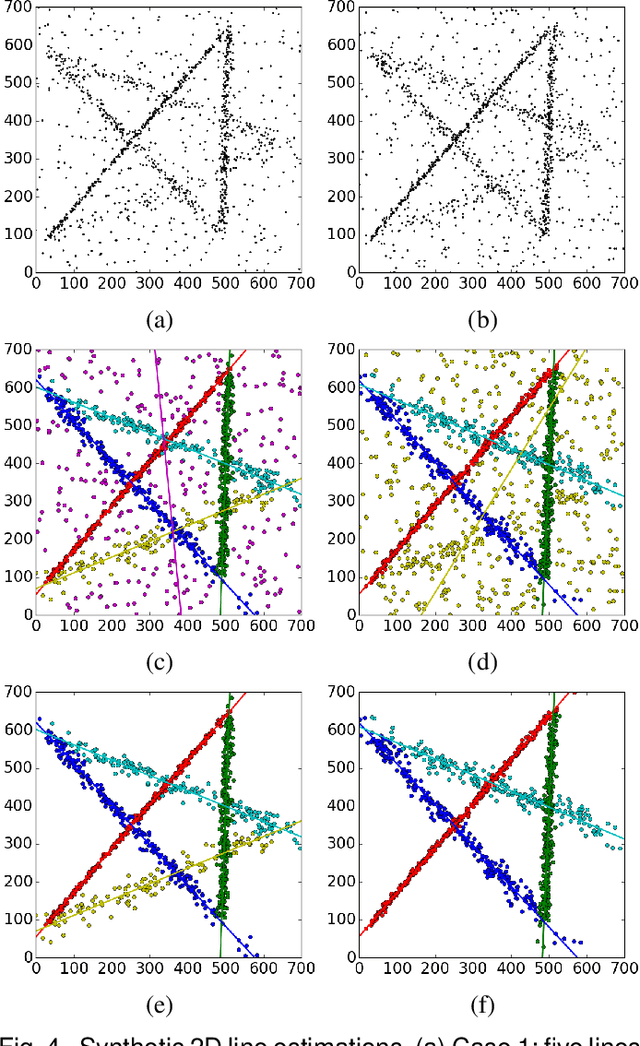
The robust estimator presented in this paper processes each structure independently. The scales of the structures are estimated adaptively and no threshold is involved in spite of different objective functions. The user has to specify only the number of elemental subsets for random sampling. After classifying all the input data, the segmented structures are sorted by their strengths and the strongest inlier structures come out at the top. Like any robust estimators, this algorithm also has limitations which are described in detail. Several synthetic and real examples are presented to illustrate every aspect of the algorithm.
Local Variation as a Statistical Hypothesis Test
Apr 24, 2015



The goal of image oversegmentation is to divide an image into several pieces, each of which should ideally be part of an object. One of the simplest and yet most effective oversegmentation algorithms is known as local variation (LV) (Felzenszwalb and Huttenlocher 2004). In this work, we study this algorithm and show that algorithms similar to LV can be devised by applying different statistical models and decisions, thus providing further theoretical justification and a well-founded explanation for the unexpected high performance of the LV approach. Some of these algorithms are based on statistics of natural images and on a hypothesis testing decision; we denote these algorithms probabilistic local variation (pLV). The best pLV algorithm, which relies on censored estimation, presents state-of-the-art results while keeping the same computational complexity of the LV algorithm.