 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Knowledge Extraction from LLMs for Robotic Task Learning through Agent Analysis
Jun 15, 2023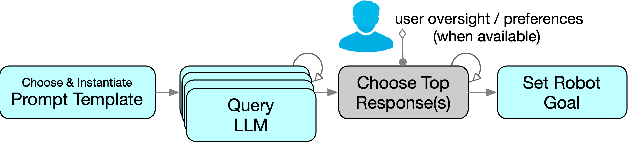



Large language models (LLMs) offer significant promise as a knowledge source for robotic task learning. Prompt engineering has been shown to be effective for eliciting knowledge from an LLM but alone is insufficient for acquiring relevant, situationally grounded knowledge for an embodied robotic agent learning novel tasks. We describe a cognitive-agent approach that extends and complements prompt engineering, mitigating its limitations, and thus enabling a robot to acquire new task knowledge matched to its native language capabilities, embodiment, environment, and user preferences. The approach is to increase the response space of LLMs and deploy general strategies, embedded within the autonomous robot, to evaluate, repair, and select among candidate responses produced by the LLM. We describe the approach and experiments that show how a robot, by retrieving and evaluating a breadth of responses from the LLM, can achieve >75% task completion in one-shot learning without user oversight. The approach achieves 100% task completion when human oversight (such as indication of preference) is provided, while greatly reducing how much human oversight is needed.
Improving Language Model Prompting in Support of Semi-autonomous Task Learning
Sep 13, 2022
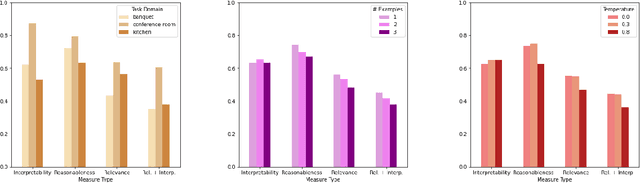

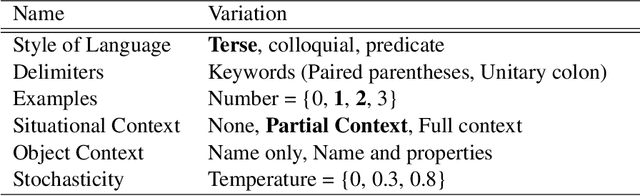
Language models (LLMs) offer potential as a source of knowledge for agents that need to acquire new task competencies within a performance environment. We describe efforts toward a novel agent capability that can construct cues (or "prompts") that result in useful LLM responses for an agent learning a new task. Importantly, responses must not only be "reasonable" (a measure used commonly in research on knowledge extraction from LLMs) but also specific to the agent's task context and in a form that the agent can interpret given its native language capacities. We summarize a series of empirical investigations of prompting strategies and evaluate responses against the goals of targeted and actionable responses for task learning. Our results demonstrate that actionable task knowledge can be obtained from LLMs in support of online agent task learning.
Evaluating Diverse Knowledge Sources for Online One-shot Learning of Novel Tasks
Aug 19, 2022
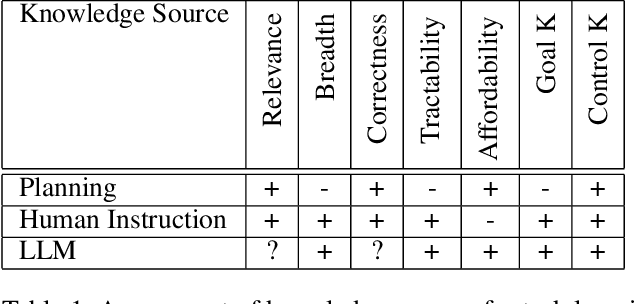

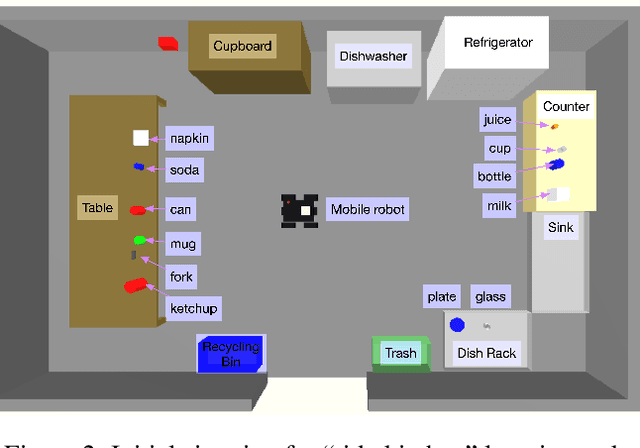
Online autonomous agents are able to draw on a wide variety of potential sources of task knowledge; however current approaches invariably focus on only one or two. Here we investigate the challenges and impact of exploiting diverse knowledge sources to learn, in one-shot, new tasks for a simulated household mobile robot. The resulting agent, developed in the Soar cognitive architecture, uses the following sources of domain and task knowledge: interaction with the environment, task execution and planning knowledge, human natural language instruction, and responses retrieved from a large language model (GPT-3). We explore the distinct contributions of these knowledge sources and evaluate the performance of different combinations in terms of learning correct task knowledge, human workload, and computational costs. The results from combining all sources demonstrate that integration improves one-shot task learning overall in terms of computational costs and human workload.