 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Information Bottleneck
Mar 03, 2021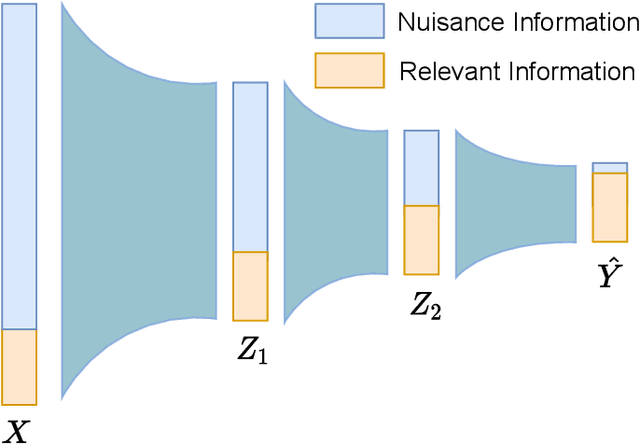


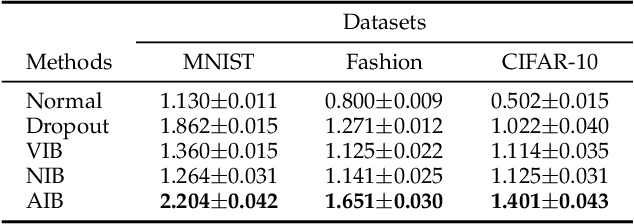
The information bottleneck (IB) principle has been adopted to explain deep learning in terms of information compression and prediction, which are balanced by a trade-off hyperparameter. How to optimize the IB principle for better robustness and figure out the effects of compression through the trade-off hyperparameter are two challenging problems. Previous methods attempted to optimize the IB principle by introducing random noise into learning the representation and achieved state-of-the-art performance in the nuisance information compression and semantic information extraction. However, their performance on resisting adversarial perturbations is far less impressive. To this end, we propose an adversarial information bottleneck (AIB) method without any explicit assumptions about the underlying distribution of the representations, which can be optimized effectively by solving a Min-Max optimization problem. Numerical experiments on synthetic and real-world datasets demonstrate its effectiveness on learning more invariant representations and mitigating adversarial perturbations compared to several competing IB methods. In addition, we analyse the adversarial robustness of diverse IB methods contrasting with their IB curves, and reveal that IB models with the hyperparameter $\beta$ corresponding to the knee point in the IB curve achieve the best trade-off between compression and prediction, and has best robustness against various attacks.
Learnable Graph-regularization for Matrix Decomposition
Oct 16, 2020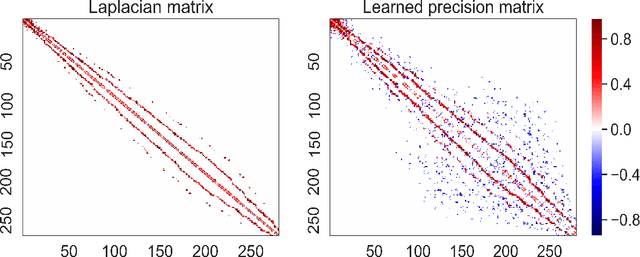

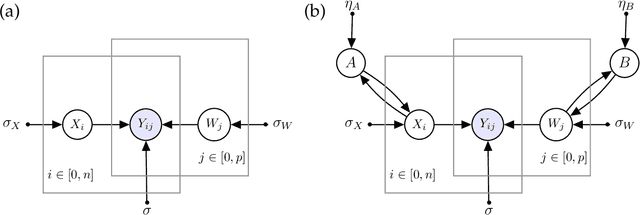

Low-rank approximation models of data matrices have become important machine learning and data mining tools in many fields including computer vision, text mining, bioinformatics and many others. They allow for embedding high-dimensional data into low-dimensional spaces, which mitigates the effects of noise and uncovers latent relations. In order to make the learned representations inherit the structures in the original data, graph-regularization terms are often added to the loss function. However, the prior graph construction often fails to reflect the true network connectivity and the intrinsic relationships. In addition, many graph-regularized methods fail to take the dual spaces into account. Probabilistic models are often used to model the distribution of the representations, but most of previous methods often assume that the hidden variables are independent and identically distributed for simplicity. To this end, we propose a learnable graph-regularization model for matrix decomposition (LGMD), which builds a bridge between graph-regularized methods and probabilistic matrix decomposition models. LGMD learns two graphical structures (i.e., two precision matrices) in real-time in an iterative manner via sparse precision matrix estimation and is more robust to noise and missing entries. Extensive numerical results and comparison with competing methods demonstrate its effectiveness.