 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Merge of k-NN Graph
Aug 27, 2019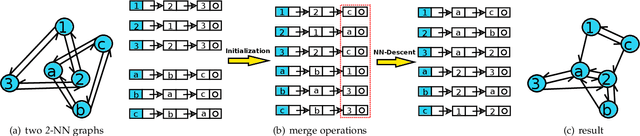
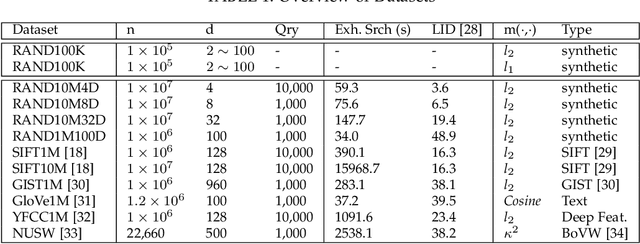
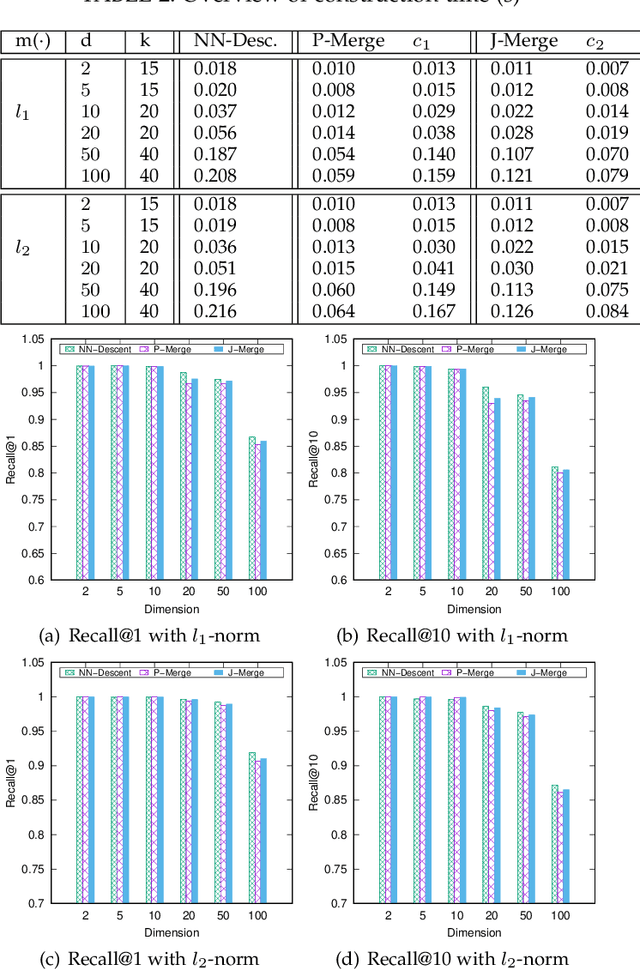
k-nearest neighbor graph is the fundamental data structure in many disciplines such as information retrieval, data-mining, pattern recognition and machine learning, etc. In the literature, considerable research has been focusing on how to efficiently build an approximate k-nearest neighbor graph (k-NN graph) for a fixed dataset. Unfortunately, a closely related issue to the graph construction has been long overlooked. Namely, few literature covers about how to merge two existing k-NN graphs. In this paper, we address the k-NN graph merge issue of two different scenarios. On the first hand, peer merge is proposed to address the problem of merging two approximate k-NN graphs into one. This makes parallel approximate k-NN graph computation in large-scale become possible. In addition, the problem of merging a raw set into a built k-NN graph is also addressed by joint merge. It allows the approximate k-NN graph to be built incrementally. It therefore supports approximate k-NN graph construction for an open set. Moreover, deriving from joint merge, an hierarchical approximate k-NN graph construction approach is presented. With the support of produced graph hierarchy, superior performance is observed on the large-scale NN search task across various data types and data dimensions, and under different distance measures.
A Comparative Study on Hierarchical Navigable Small World Graphs
Apr 12, 2019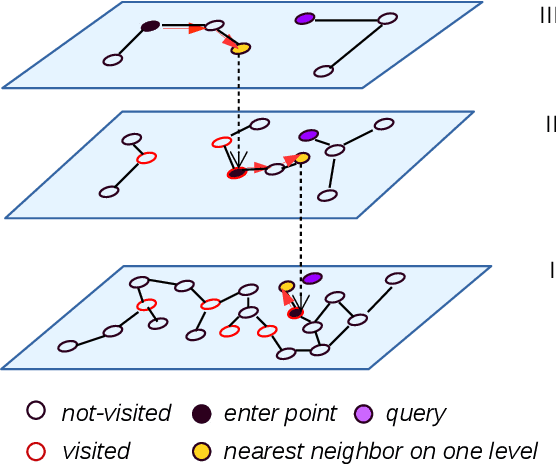
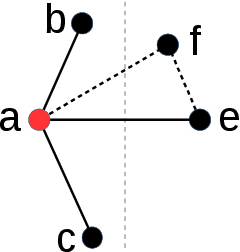


Hierarchical navigable small world (HNSW) graphs get more and more popular on large-scale nearest neighbor search tasks since the source codes were released two years ago. The attractiveness of this approach lies in its superior performance over most of the known nearest neighbor search approaches as well as its genericness to various distance measures. In this paper, several comparative studies have been conducted on this search approach. The role of hierarchical structure in HNSW and the function of HNSW graph itself are investigated. We find that the hierarchical structure in HNSW could not achieve "a much better logarithmic complexity scaling" as it was claimed in the paper, particularly on high dimensional data. Moreover, we find that similar high search speed efficiency as HNSW could be achieved with the support of flat k-NN graph after graph diversification. Finally, we point out the difficulty, that is faced by most of the graph based search approaches, is directly linked to "curse of dimensionality". HNSW, like other graph based approaches, is unable to address such difficulty.