 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-shaped and Inverted-U Scaling behind Emergent Abilities of Large Language Models
Oct 02, 2024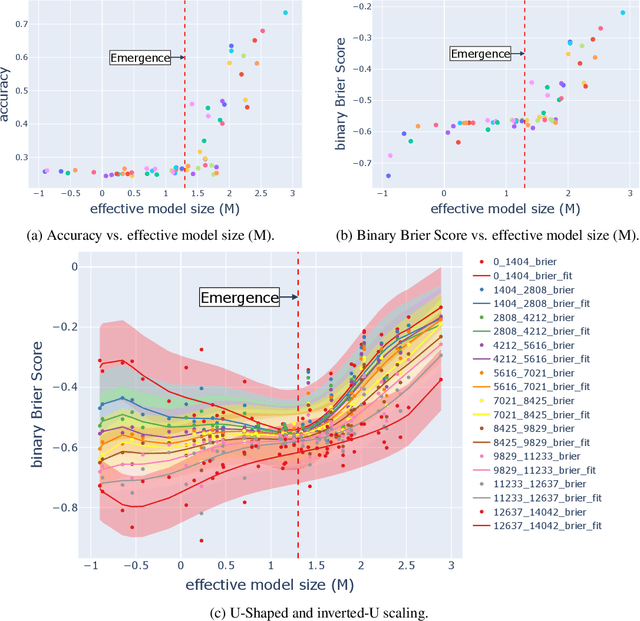
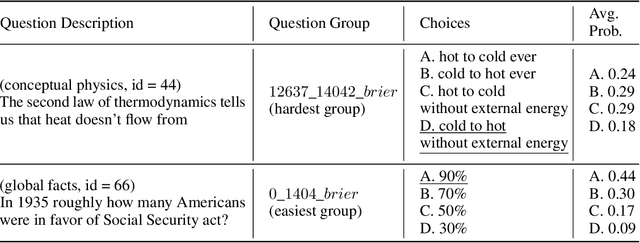
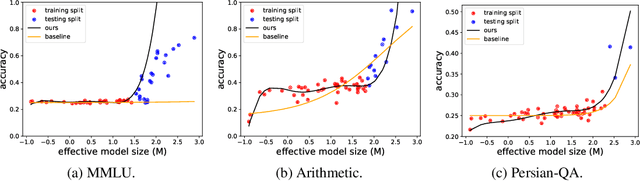
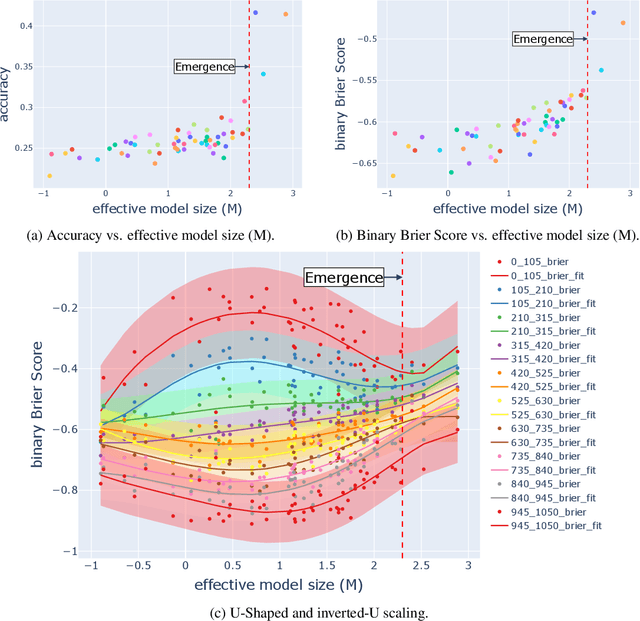
Large language models (LLMs) have been shown to exhibit emergent abilities in some downstream tasks, where performance seems to stagnate at first and then improve sharply and unpredictably with scale beyond a threshold. By dividing questions in the datasets according to difficulty level by average performance, we observe U-shaped scaling for hard questions, and inverted-U scaling followed by steady improvement for easy questions. Moreover, the emergence threshold roughly coincides with the point at which performance on easy questions reverts from inverse scaling to standard scaling. Capitalizing on the observable though opposing scaling trend on easy and hard questions, we propose a simple yet effective pipeline, called Slice-and-Sandwich, to predict both the emergence threshold and model performance beyond the threshold.