 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduction Techniques for Global Bayesian Optimisation
Dec 12, 2024



Bayesian Optimisation (BO) is a state-of-the-art global optimisation technique for black-box problems where derivative information is unavailable, and sample efficiency is crucial. However, improving the general scalability of BO has proved challenging. Here, we explore Latent Space Bayesian Optimisation (LSBO), that applies dimensionality reduction to perform BO in a reduced-dimensional subspace. While early LSBO methods used (linear) random projections (Wang et al., 2013), we employ Variational Autoencoders (VAEs) to manage more complex data structures and general DR tasks. Building on Grosnit et. al. (2021), we analyse the VAE-based LSBO framework, focusing on VAE retraining and deep metric loss. We suggest a few key corrections in their implementation, originally designed for tasks such as molecule generation, and reformulate the algorithm for broader optimisation purposes. Our numerical results show that structured latent manifolds improve BO performance. Additionally, we examine the use of the Mat\'{e}rn-$\frac{5}{2}$ kernel for Gaussian Processes in this LSBO context. We also integrate Sequential Domain Reduction (SDR), a standard global optimization efficiency strategy, into BO. SDR is included in a GPU-based environment using \textit{BoTorch}, both in the original and VAE-generated latent spaces, marking the first application of SDR within LSBO.
PCENet: High Dimensional Surrogate Modeling for Learning Uncertainty
Feb 11, 2022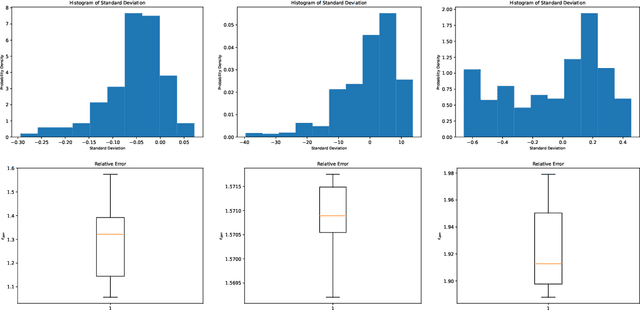
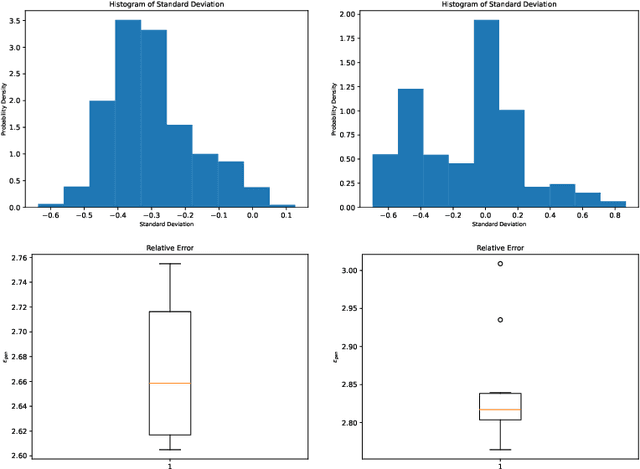
Learning data representations under uncertainty is an important task that emerges in numerous machine learning applications. However, uncertainty quantification (UQ) techniques are computationally intensive and become prohibitively expensive for high-dimensional data. In this paper, we present a novel surrogate model for representation learning and uncertainty quantification, which aims to deal with data of moderate to high dimensions. The proposed model combines a neural network approach for dimensionality reduction of the (potentially high-dimensional) data, with a surrogate model method for learning the data distribution. We first employ a variational autoencoder (VAE) to learn a low-dimensional representation of the data distribution. We then propose to harness polynomial chaos expansion (PCE) formulation to map this distribution to the output target. The coefficients of PCE are learned from the distribution representation of the training data using a maximum mean discrepancy (MMD) approach. Our model enables us to (a) learn a representation of the data, (b) estimate uncertainty in the high-dimensional data system, and (c) match high order moments of the output distribution; without any prior statistical assumptions on the data. Numerical experimental results are presented to illustrate the performance of the proposed method.
Gauss-Legendre Features for Gaussian Process Regression
Jan 05, 2021
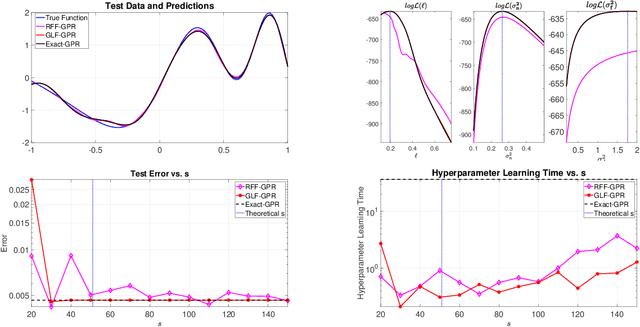

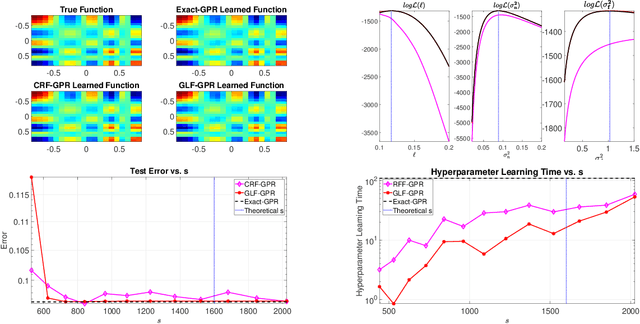
Gaussian processes provide a powerful probabilistic kernel learning framework, which allows learning high quality nonparametric regression models via methods such as Gaussian process regression. Nevertheless, the learning phase of Gaussian process regression requires massive computations which are not realistic for large datasets. In this paper, we present a Gauss-Legendre quadrature based approach for scaling up Gaussian process regression via a low rank approximation of the kernel matrix. We utilize the structure of the low rank approximation to achieve effective hyperparameter learning, training and prediction. Our method is very much inspired by the well-known random Fourier features approach, which also builds low-rank approximations via numerical integration. However, our method is capable of generating high quality approximation to the kernel using an amount of features which is poly-logarithmic in the number of training points, while similar guarantees will require an amount that is at the very least linear in the number of training points when random Fourier features. Furthermore, the structure of the low-rank approximation that our method builds is subtly different from the one generated by random Fourier features, and this enables much more efficient hyperparameter learning. The utility of our method for learning with low-dimensional datasets is demonstrated using numerical experiments.