 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy on Inter and Intra Speaker Variability in Speaker Recognition
Nov 12, 2024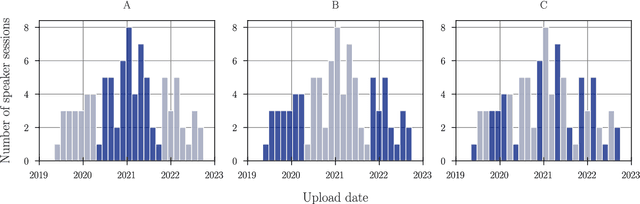
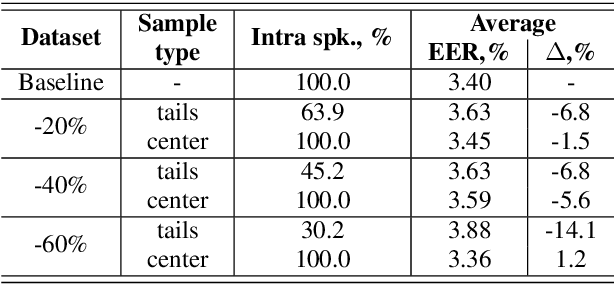
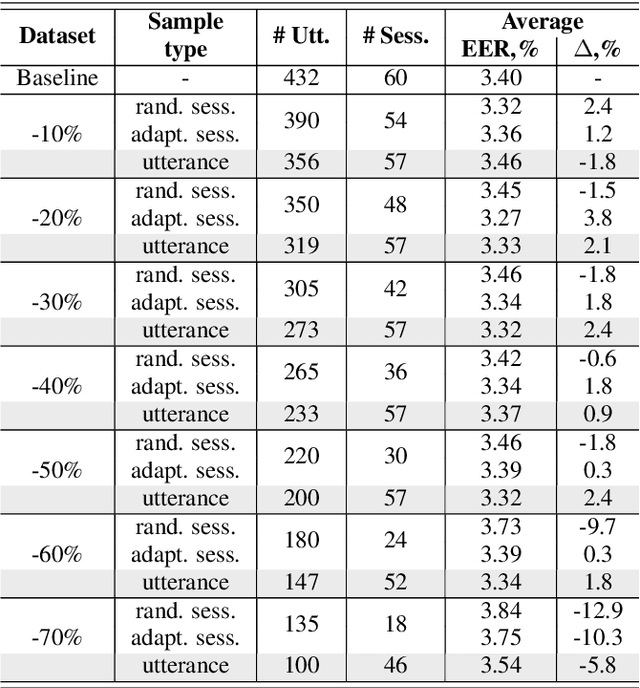
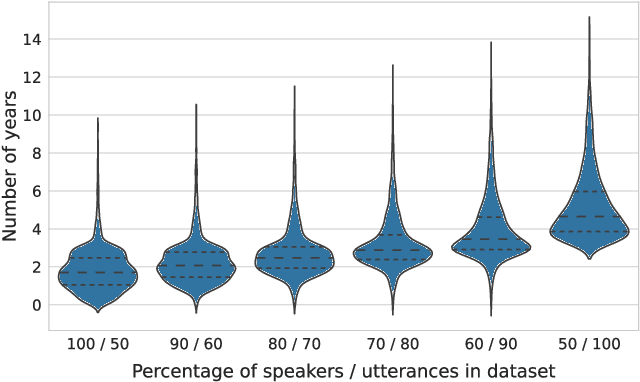
Optimization of a trade-off between the number of speakers and their temporal variability (or session diversity) is crucial for the development of a speaker recognition system together with making the data collection process feasible from a time perspective. In this article, we provide the analysis of dependency between inter and intra speaker variability in training data for the modern neural network-based speaker recognition system using the VoxTube dataset for text-independent speaker recognition task. Besides, an auxiliary contribution of this work is a release of upload date metadata per utterance in a VoxTube dataset. We want this article to contribute to guidelines and best practices for collecting and filtering data from media hosting platforms to facilitate the efforts of researchers in developing speaker recognition systems.
Reshape Dimensions Network for Speaker Recognition
Jul 25, 2024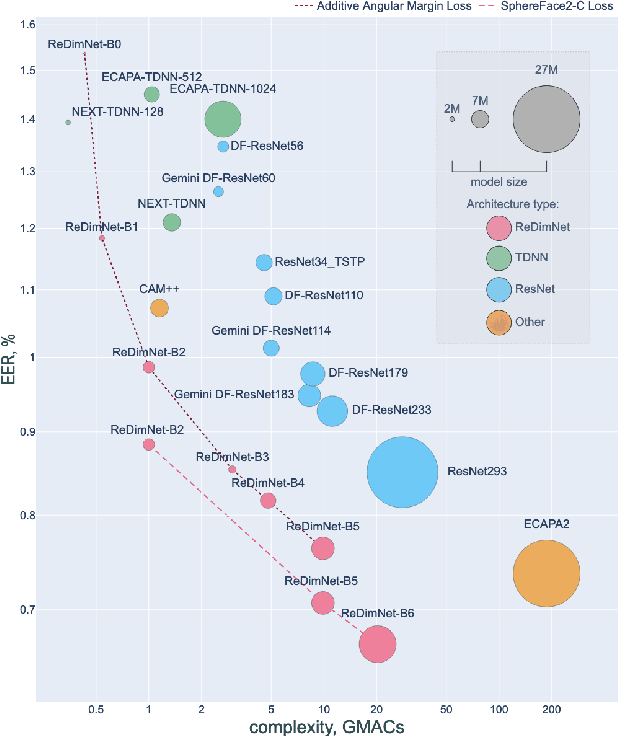

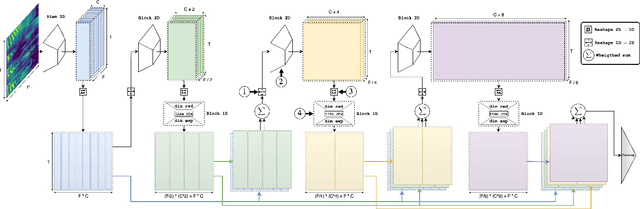
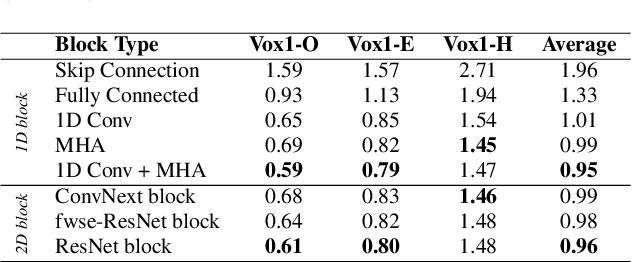
In this paper, we present Reshape Dimensions Network (ReDimNet), a novel neural network architecture for extracting utterance-level speaker representations. Our approach leverages dimensionality reshaping of 2D feature maps to 1D signal representation and vice versa, enabling the joint usage of 1D and 2D blocks. We propose an original network topology that preserves the volume of channel-timestep-frequency outputs of 1D and 2D blocks, facilitating efficient residual feature maps aggregation. Moreover, ReDimNet is efficiently scalable, and we introduce a range of model sizes, varying from 1 to 15 M parameters and from 0.5 to 20 GMACs. Our experimental results demonstrate that ReDimNet achieves state-of-the-art performance in speaker recognition while reducing computational complexity and the number of model parameters.
The ID R&D VoxCeleb Speaker Recognition Challenge 2023 System Description
Aug 20, 2023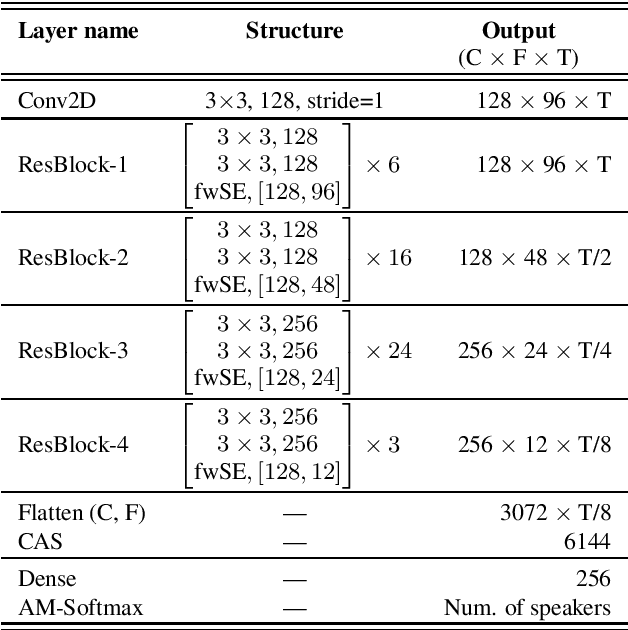
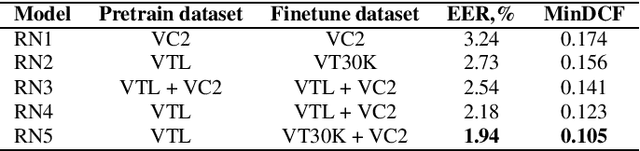
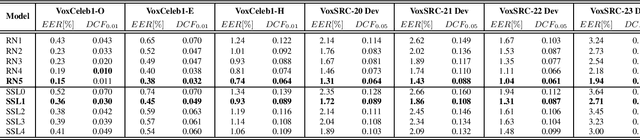

This report describes ID R&D team submissions for Track 2 (open) to the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our solution is based on the fusion of deep ResNets and self-supervised learning (SSL) based models trained on a mixture of a VoxCeleb2 dataset and a large version of a VoxTube dataset. The final submission to the Track 2 achieved the first place on the VoxSRC-23 public leaderboard with a minDCF(0.05) of 0.0762 and EER of 1.30%.