 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired-Sampling Contrastive Framework for Joint Physical-Digital Face Attack Detection
Aug 20, 2025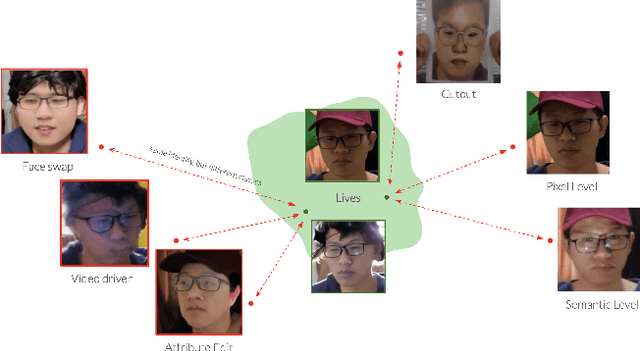
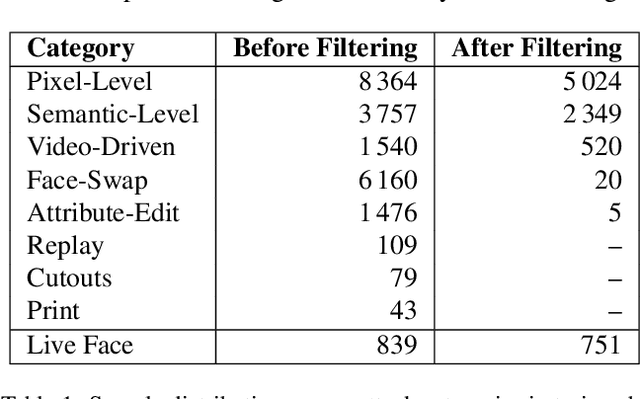

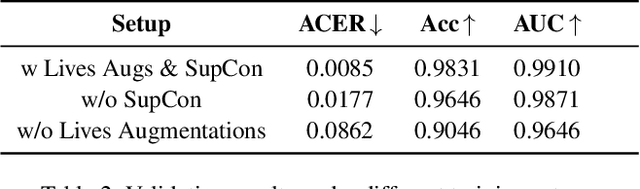
Modern face recognition systems remain vulnerable to spoofing attempts, including both physical presentation attacks and digital forgeries. Traditionally, these two attack vectors have been handled by separate models, each targeting its own artifacts and modalities. However, maintaining distinct detectors increases system complexity and inference latency and leaves systems exposed to combined attack vectors. We propose the Paired-Sampling Contrastive Framework, a unified training approach that leverages automatically matched pairs of genuine and attack selfies to learn modality-agnostic liveness cues. Evaluated on the 6th Face Anti-Spoofing Challenge Unified Physical-Digital Attack Detection benchmark, our method achieves an average classification error rate (ACER) of 2.10 percent, outperforming prior solutions. The framework is lightweight (4.46 GFLOPs) and trains in under one hour, making it practical for real-world deployment. Code and pretrained models are available at https://github.com/xPONYx/iccv2025_deepfake_challenge.
Reshape Dimensions Network for Speaker Recognition
Jul 25, 2024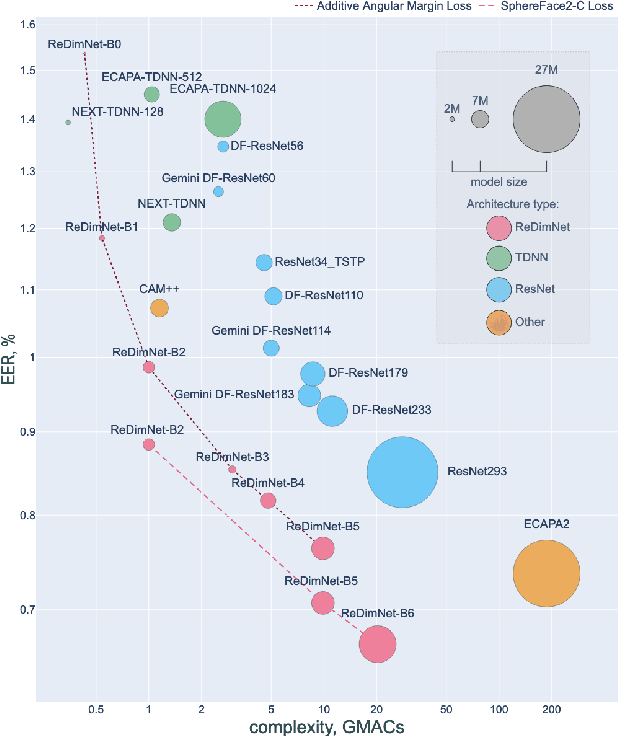

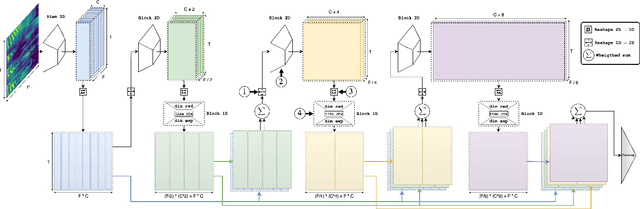
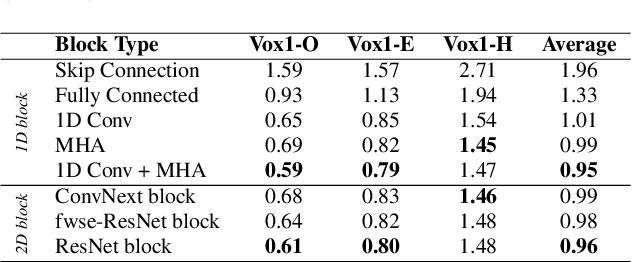
In this paper, we present Reshape Dimensions Network (ReDimNet), a novel neural network architecture for extracting utterance-level speaker representations. Our approach leverages dimensionality reshaping of 2D feature maps to 1D signal representation and vice versa, enabling the joint usage of 1D and 2D blocks. We propose an original network topology that preserves the volume of channel-timestep-frequency outputs of 1D and 2D blocks, facilitating efficient residual feature maps aggregation. Moreover, ReDimNet is efficiently scalable, and we introduce a range of model sizes, varying from 1 to 15 M parameters and from 0.5 to 20 GMACs. Our experimental results demonstrate that ReDimNet achieves state-of-the-art performance in speaker recognition while reducing computational complexity and the number of model parameters.
The ID R&D VoxCeleb Speaker Recognition Challenge 2023 System Description
Aug 20, 2023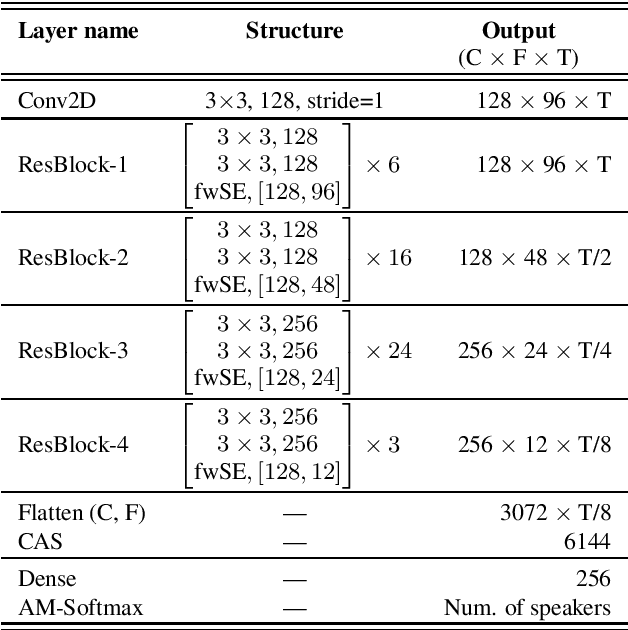
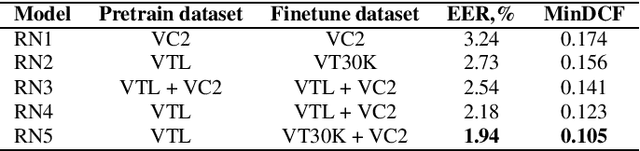
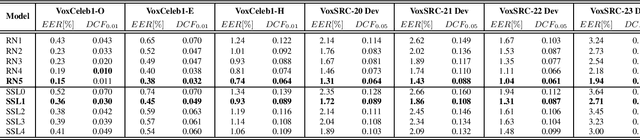

This report describes ID R&D team submissions for Track 2 (open) to the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our solution is based on the fusion of deep ResNets and self-supervised learning (SSL) based models trained on a mixture of a VoxCeleb2 dataset and a large version of a VoxTube dataset. The final submission to the Track 2 achieved the first place on the VoxSRC-23 public leaderboard with a minDCF(0.05) of 0.0762 and EER of 1.30%.