 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum likelihood estimation of a finite mixture of logistic regression models in a continuous data stream
Feb 28, 2018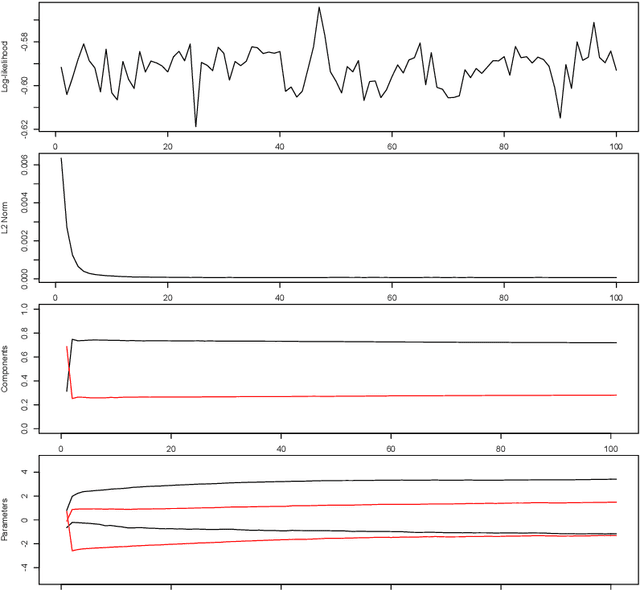

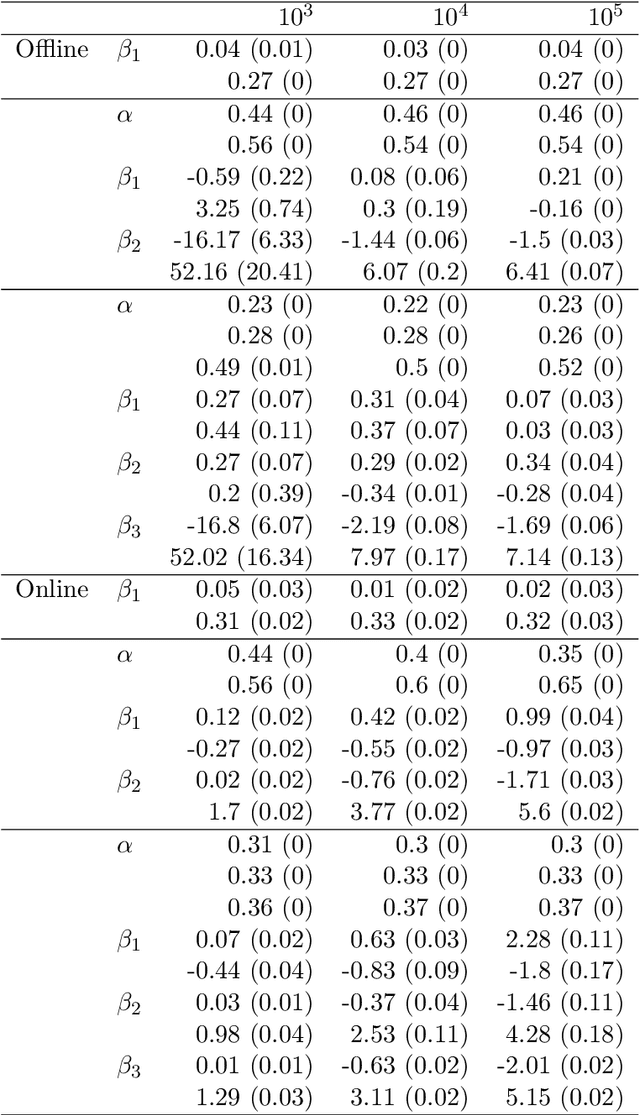

In marketing we are often confronted with a continuous stream of responses to marketing messages. Such streaming data provide invaluable information regarding message effectiveness and segmentation. However, streaming data are hard to analyze using conventional methods: their high volume and the fact that they are continuously augmented means that it takes considerable time to analyze them. We propose a method for estimating a finite mixture of logistic regression models which can be used to cluster customers based on a continuous stream of responses. This method, which we coin oFMLR, allows segments to be identified in data streams or extremely large static datasets. Contrary to black box algorithms, oFMLR provides model estimates that are directly interpretable. We first introduce oFMLR, explaining in passing general topics such as online estimation and the EM algorithm, making this paper a high level overview of possible methods of dealing with large data streams in marketing practice. Next, we discuss model convergence, identifiability, and relations to alternative, Bayesian, methods; we also identify more general issues that arise from dealing with continuously augmented data sets. Finally, we introduce the oFMLR [R] package and evaluate the method by numerical simulation and by analyzing a large customer clickstream dataset.