 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Computations for Generalized Mixed Effects Models with Crossed Random Effects Using Krylov Subspace Methods
May 14, 2025
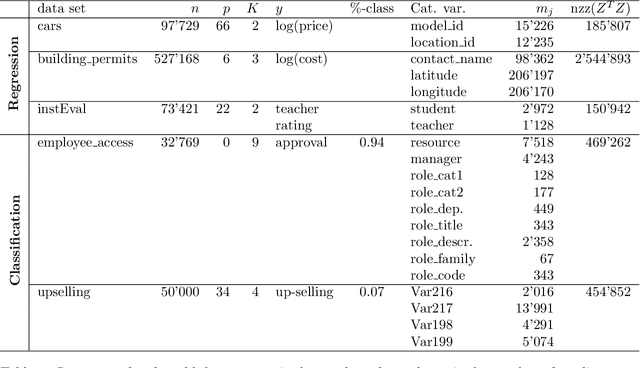
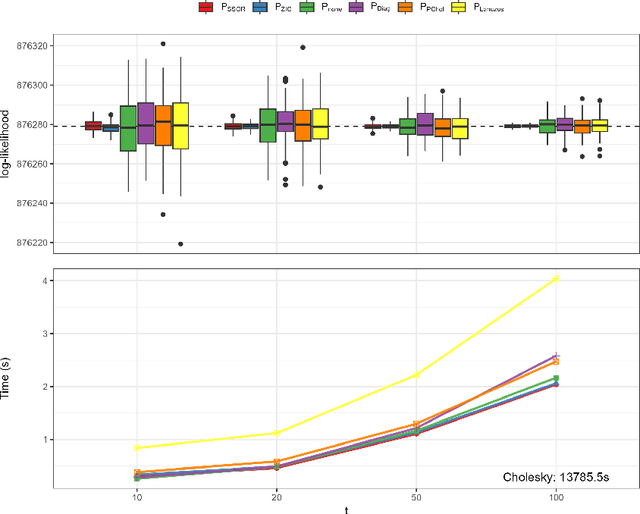
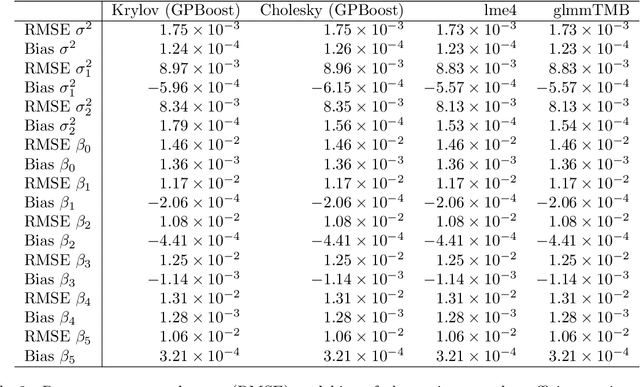
Mixed effects models are widely used for modeling data with hierarchically grouped structures and high-cardinality categorical predictor variables. However, for high-dimensional crossed random effects, current standard computations relying on Cholesky decompositions can become prohibitively slow. In this work, we present novel Krylov subspace-based methods that address several existing computational bottlenecks. Among other things, we theoretically analyze and empirically evaluate various preconditioners for the conjugate gradient and stochastic Lanczos quadrature methods, derive new convergence results, and develop computationally efficient methods for calculating predictive variances. Extensive experiments using simulated and real-world data sets show that our proposed methods scale much better than Cholesky-based computations, for instance, achieving a runtime reduction of approximately two orders of magnitudes for both estimation and prediction. Moreover, our software implementation is up to 10'000 times faster and more stable than state-of-the-art implementations such as lme4 and glmmTMB when using default settings. Our methods are implemented in the free C++ software library GPBoost with high-level Python and R packages.
A Spatio-Temporal Machine Learning Model for Mortgage Credit Risk: Default Probabilities and Loan Portfolios
Oct 03, 2024We introduce a novel machine learning model for credit risk by combining tree-boosting with a latent spatio-temporal Gaussian process model accounting for frailty correlation. This allows for modeling non-linearities and interactions among predictor variables in a flexible data-driven manner and for accounting for spatio-temporal variation that is not explained by observable predictor variables. We also show how estimation and prediction can be done in a computationally efficient manner. In an application to a large U.S. mortgage credit risk data set, we find that both predictive default probabilities for individual loans and predictive loan portfolio loss distributions obtained with our novel approach are more accurate compared to conventional independent linear hazard models and also linear spatio-temporal models. Using interpretability tools for machine learning models, we find that the likely reasons for this outperformance are strong interaction and non-linear effects in the predictor variables and the presence of large spatio-temporal frailty effects.
Iterative Methods for Vecchia-Laplace Approximations for Latent Gaussian Process Models
Oct 18, 2023Latent Gaussian process (GP) models are flexible probabilistic non-parametric function models. Vecchia approximations are accurate approximations for GPs to overcome computational bottlenecks for large data, and the Laplace approximation is a fast method with asymptotic convergence guarantees to approximate marginal likelihoods and posterior predictive distributions for non-Gaussian likelihoods. Unfortunately, the computational complexity of combined Vecchia-Laplace approximations grows faster than linearly in the sample size when used in combination with direct solver methods such as the Cholesky decomposition. Computations with Vecchia-Laplace approximations thus become prohibitively slow precisely when the approximations are usually the most accurate, i.e., on large data sets. In this article, we present several iterative methods for inference with Vecchia-Laplace approximations which make computations considerably faster compared to Cholesky-based calculations. We analyze our proposed methods theoretically and in experiments with simulated and real-world data. In particular, we obtain a speed-up of an order of magnitude compared to Cholesky-based inference and a threefold increase in prediction accuracy in terms of the continuous ranked probability score compared to a state-of-the-art method on a large satellite data set. All methods are implemented in a free C++ software library with high-level Python and R packages.