 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Drivers of Predictive Uncertainty using Variance Feature Attribution
Dec 12, 2023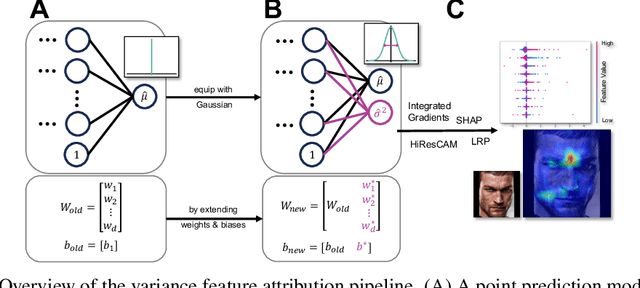
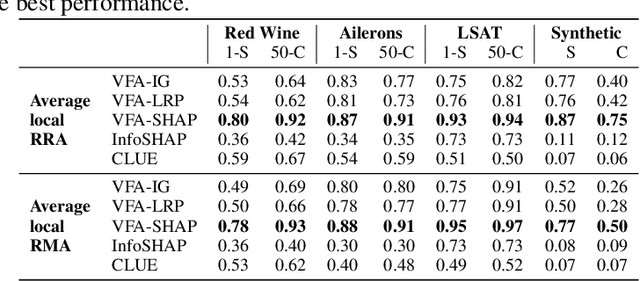
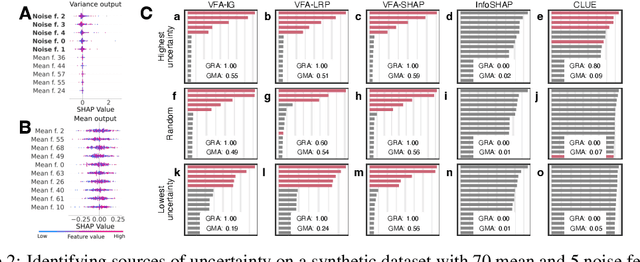

Explainability and uncertainty quantification are two pillars of trustable artificial intelligence. However, the reasoning behind uncertainty estimates is generally left unexplained. Identifying the drivers of uncertainty complements explanations of point predictions in recognizing potential model limitations. It facilitates the detection of oversimplification in the uncertainty estimation process. Explanations of uncertainty enhance communication and trust in decisions. They allow for verifying whether the main drivers of model uncertainty are relevant and may impact model usage. So far, the subject of explaining uncertainties has been rarely studied. The few exceptions in existing literature are tailored to Bayesian neural networks or rely heavily on technically intricate approaches, hindering their broad adoption. We propose variance feature attribution, a simple and scalable solution to explain predictive aleatoric uncertainties. First, we estimate uncertainty as predictive variance by equipping a neural network with a Gaussian output distribution by adding a variance output neuron. Thereby, we can rely on pre-trained point prediction models and fine-tune them for meaningful variance estimation. Second, we apply out-of-the-box explainers on the variance output of these models to explain the uncertainty estimation. We evaluate our approach in a synthetic setting where the data-generating process is known. We show that our method can explain uncertainty influences more reliably and faster than the established baseline CLUE. We fine-tune a state-of-the-art age regression model to estimate uncertainty and obtain attributions. Our explanations highlight potential sources of uncertainty, such as laugh lines. Variance feature attribution provides accurate explanations for uncertainty estimates with little modifications to the model architecture and low computational overhead.
SimbaML: Connecting Mechanistic Models and Machine Learning with Augmented Data
Apr 08, 2023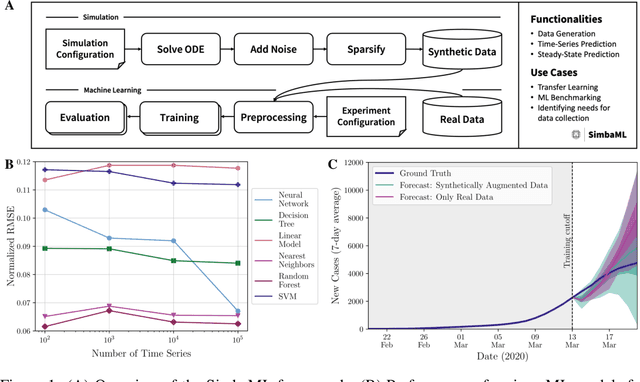
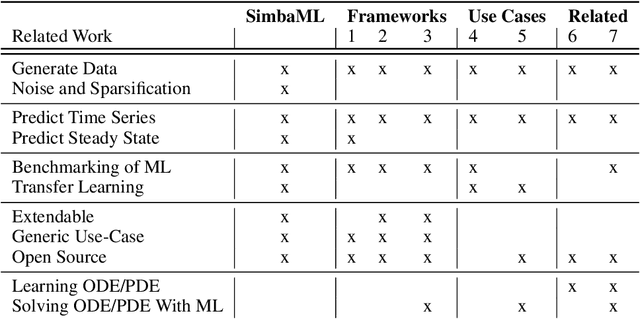
Training sophisticated machine learning (ML) models requires large datasets that are difficult or expensive to collect for many applications. If prior knowledge about system dynamics is available, mechanistic representations can be used to supplement real-world data. We present SimbaML (Simulation-Based ML), an open-source tool that unifies realistic synthetic dataset generation from ordinary differential equation-based models and the direct analysis and inclusion in ML pipelines. SimbaML conveniently enables investigating transfer learning from synthetic to real-world data, data augmentation, identifying needs for data collection, and benchmarking physics-informed ML approaches. SimbaML is available from https://pypi.org/project/simba-ml/.