 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-free Statistically Consistent Interpolation: Dimension-independent Convergence Rates for Hilbert kernel regression
Jun 07, 2021
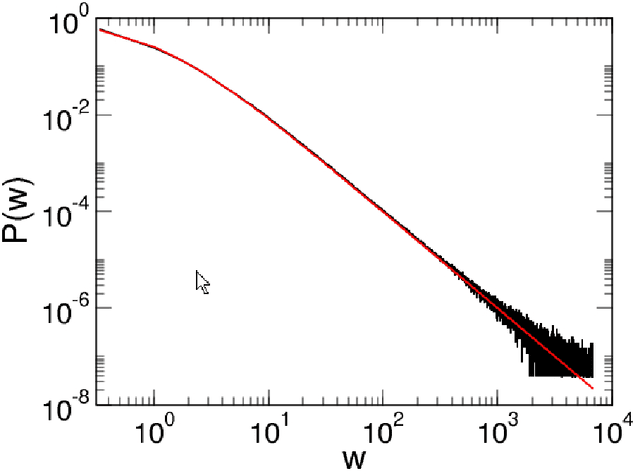
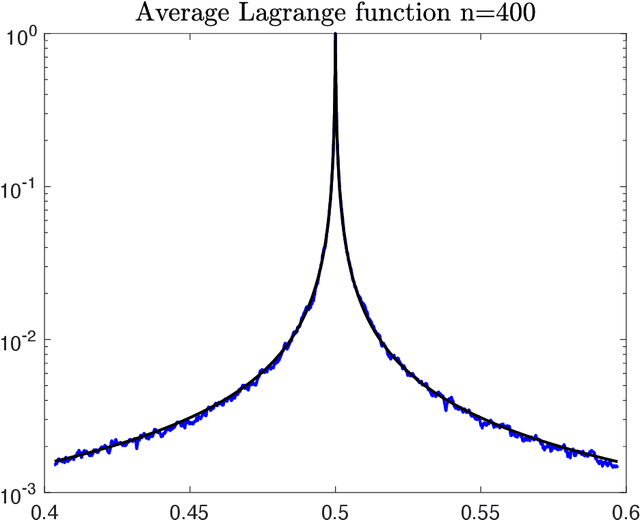
Previously, statistical textbook wisdom has held that interpolating noisy data will generalize poorly, but recent work has shown that data interpolation schemes can generalize well. This could explain why overparameterized deep nets do not necessarily overfit. Optimal data interpolation schemes have been exhibited that achieve theoretical lower bounds for excess risk in any dimension for large data (Statistically Consistent Interpolation). These are non-parametric Nadaraya-Watson estimators with singular kernels. The recently proposed weighted interpolating nearest neighbors method (wiNN) is in this class, as is the previously studied Hilbert kernel interpolation scheme, in which the estimator has the form $\hat{f}(x)=\sum_i y_i w_i(x)$, where $w_i(x)= \|x-x_i\|^{-d}/\sum_j \|x-x_j\|^{-d}$. This estimator is unique in being completely parameter-free. While statistical consistency was previously proven, convergence rates were not established. Here, we comprehensively study the finite sample properties of Hilbert kernel regression. We prove that the excess risk is asymptotically equivalent pointwise to $\sigma^2(x)/\ln(n)$ where $\sigma^2(x)$ is the noise variance. We show that the excess risk of the plugin classifier is less than $2|f(x)-1/2|^{1-\alpha}\,(1+\varepsilon)^\alpha \sigma^\alpha(x)(\ln(n))^{-\frac{\alpha}{2}}$, for any $0<\alpha<1$, where $f$ is the regression function $x\mapsto\mathbb{E}[y|x]$. We derive asymptotic equivalents of the moments of the weight functions $w_i(x)$ for large $n$, for instance for $\beta>1$, $\mathbb{E}[w_i^{\beta}(x)]\sim_{n\rightarrow \infty}((\beta-1)n\ln(n))^{-1}$. We derive an asymptotic equivalent for the Lagrange function and exhibit the nontrivial extrapolation properties of this estimator. We present heuristic arguments for a universal $w^{-2}$ power-law behavior of the probability density of the weights in the large $n$ limit.
Fitting Elephants
Mar 31, 2021



Textbook wisdom advocates for smooth function fits and implies that interpolation of noisy data should lead to poor generalization. A related heuristic is that fitting parameters should be fewer than measurements (Occam's Razor). Surprisingly, contemporary machine learning (ML) approaches, cf. deep nets (DNNs), generalize well despite interpolating noisy data. This may be understood via Statistically Consistent Interpolation (SCI), i.e. data interpolation techniques that generalize optimally for big data. In this article we elucidate SCI using the weighted interpolating nearest neighbors (wiNN) algorithm, which adds singular weight functions to kNN (k-nearest neighbors). This shows that data interpolation can be a valid ML strategy for big data. SCI clarifies the relation between two ways of modeling natural phenomena: the rationalist approach (strong priors) of theoretical physics with few parameters and the empiricist (weak priors) approach of modern ML with more parameters than data. SCI shows that the purely empirical approach can successfully predict. However data interpolation does not provide theoretical insights, and the training data requirements may be prohibitive. Complex animal brains are between these extremes, with many parameters, but modest training data, and with prior structure encoded in species-specific mesoscale circuitry. Thus, modern ML provides a distinct epistemological approach different both from physical theories and animal brains.
Understanding overfitting peaks in generalization error: Analytical risk curves for $l_2$ and $l_1$ penalized interpolation
Jun 09, 2019
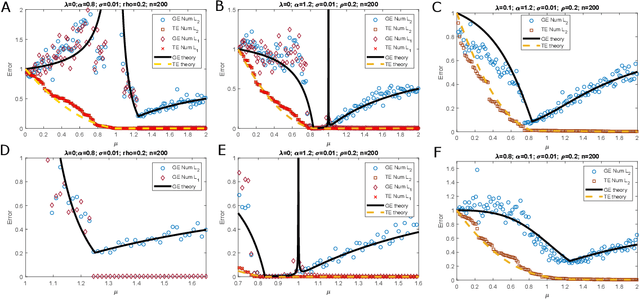
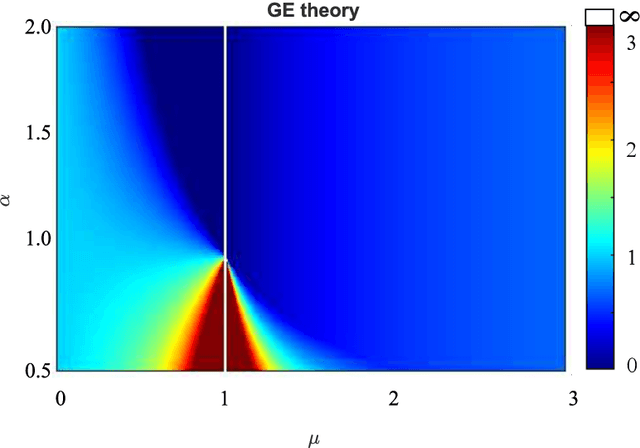
Traditionally in regression one minimizes the number of fitting parameters or uses smoothing/regularization to trade training (TE) and generalization error (GE). Driving TE to zero by increasing fitting degrees of freedom (dof) is expected to increase GE. However modern big-data approaches, including deep nets, seem to over-parametrize and send TE to zero (data interpolation) without impacting GE. Overparametrization has the benefit that global minima of the empirical loss function proliferate and become easier to find. These phenomena have drawn theoretical attention. Regression and classification algorithms have been shown that interpolate data but also generalize optimally. An interesting related phenomenon has been noted: the existence of non-monotonic risk curves, with a peak in GE with increasing dof. It was suggested that this peak separates a classical regime from a modern regime where over-parametrization improves performance. Similar over-fitting peaks were reported previously (statistical physics approach to learning) and attributed to increased fitting model flexibility. We introduce a generative and fitting model pair ("Misparametrized Sparse Regression" or MiSpaR) and show that the overfitting peak can be dissociated from the point at which the fitting function gains enough dof's to match the data generative model and thus provides good generalization. This complicates the interpretation of overfitting peaks as separating a "classical" from a "modern" regime. Data interpolation itself cannot guarantee good generalization: we need to study the interpolation with different penalty terms. We present analytical formulae for GE curves for MiSpaR with $l_2$ and $l_1$ penalties, in the interpolating limit $\lambda\rightarrow 0$.These risk curves exhibit important differences and help elucidate the underlying phenomena.
Fast Convergence for Stochastic and Distributed Gradient Descent in the Interpolation Limit
May 29, 2018Modern supervised learning techniques, particularly those using deep nets, involve fitting high dimensional labelled data sets with functions containing very large numbers of parameters. Much of this work is empirical. Interesting phenomena have been observed that require theoretical explanations; however the non-convexity of the loss functions complicates the analysis. Recently it has been proposed that the success of these techniques rests partly in the effectiveness of the simple stochastic gradient descent algorithm in the so called interpolation limit in which all labels are fit perfectly. This analysis is made possible since the SGD algorithm reduces to a stochastic linear system near the interpolating minimum of the loss function. Here we exploit this insight by presenting and analyzing a new distributed algorithm for gradient descent, also in the interpolating limit. The distributed SGD algorithm presented in the paper corresponds to gradient descent applied to a simple penalized distributed loss function, $L({\bf w}_1,...,{\bf w}_n) = \Sigma_i l_i({\bf w}_i) + \mu \sum_{<i,j>}|{\bf w}_i-{\bf w}_j|^2$. Here each node holds only one sample, and its own parameter vector. The notation $<i,j>$ denotes edges of a connected graph defining the links between nodes. It is shown that this distributed algorithm converges linearly (ie the error reduces exponentially with iteration number), with a rate $1-\frac{\eta}{n}\lambda_{min}(H)<R<1$ where $\lambda_{min}(H)$ is the smallest nonzero eigenvalue of the sample covariance or the Hessian H. In contrast with previous usage of similar penalty functions to enforce consensus between nodes, in the interpolating limit it is not required to take the penalty parameter to infinity for consensus to occur. The analysis further reinforces the utility of the interpolation limit in the theoretical treatment of modern machine learning algorithms.