 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-free Statistically Consistent Interpolation: Dimension-independent Convergence Rates for Hilbert kernel regression
Paper and Code
Jun 07, 2021
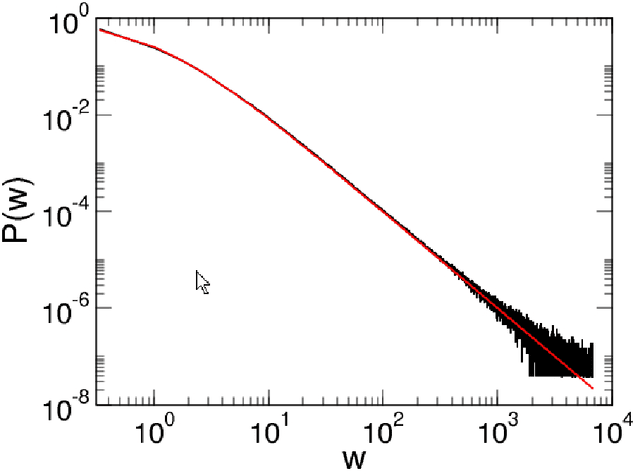
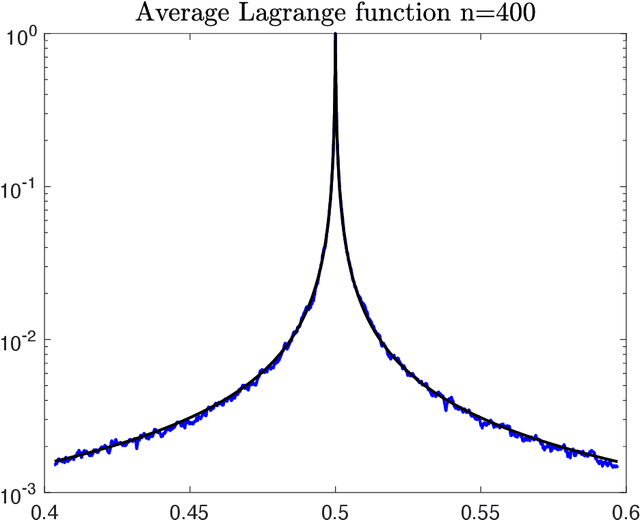
Previously, statistical textbook wisdom has held that interpolating noisy data will generalize poorly, but recent work has shown that data interpolation schemes can generalize well. This could explain why overparameterized deep nets do not necessarily overfit. Optimal data interpolation schemes have been exhibited that achieve theoretical lower bounds for excess risk in any dimension for large data (Statistically Consistent Interpolation). These are non-parametric Nadaraya-Watson estimators with singular kernels. The recently proposed weighted interpolating nearest neighbors method (wiNN) is in this class, as is the previously studied Hilbert kernel interpolation scheme, in which the estimator has the form $\hat{f}(x)=\sum_i y_i w_i(x)$, where $w_i(x)= \|x-x_i\|^{-d}/\sum_j \|x-x_j\|^{-d}$. This estimator is unique in being completely parameter-free. While statistical consistency was previously proven, convergence rates were not established. Here, we comprehensively study the finite sample properties of Hilbert kernel regression. We prove that the excess risk is asymptotically equivalent pointwise to $\sigma^2(x)/\ln(n)$ where $\sigma^2(x)$ is the noise variance. We show that the excess risk of the plugin classifier is less than $2|f(x)-1/2|^{1-\alpha}\,(1+\varepsilon)^\alpha \sigma^\alpha(x)(\ln(n))^{-\frac{\alpha}{2}}$, for any $0<\alpha<1$, where $f$ is the regression function $x\mapsto\mathbb{E}[y|x]$. We derive asymptotic equivalents of the moments of the weight functions $w_i(x)$ for large $n$, for instance for $\beta>1$, $\mathbb{E}[w_i^{\beta}(x)]\sim_{n\rightarrow \infty}((\beta-1)n\ln(n))^{-1}$. We derive an asymptotic equivalent for the Lagrange function and exhibit the nontrivial extrapolation properties of this estimator. We present heuristic arguments for a universal $w^{-2}$ power-law behavior of the probability density of the weights in the large $n$ limit.